(tagged all chữ nôm characters as language "vi-hani" so that enabled browsers (like mine) may use a Vietnamese font to render them (available fonts are: "Nom Na Tong" and "HAN NOM A" & "HAN NOM B")) (current)
It seems that vi-nom is identical to Nom Na Tong, and distinct from the default font:
羅吧固𧵑得𥪝𤄯𠊛与今骨 (default)
羅吧固𧵑得𥪝𤄯𠊛与今骨vi-nom
羅吧固𧵑得𥪝𤄯𠊛与今骨 Nom Na Tong
Compare the default font to HAN NOM A and HAN NOM B:
羅吧固𧵑得𥪝𤄯𠊛与今骨 (default)
羅吧固𧵑得𥪝𤄯𠊛与今骨 HAN NOM A
羅吧固𧵑得𥪝𤄯𠊛与今骨 HAN NOM B
HAN NOM A has an extremely subtle variation on the third character. HAN NOM B has similar variation on the eighth character. But essentially these three fonts are identical. I suggest dropping both HAN NOM A and HAN NOM B from the vi-nom template. Do you think it would help to replace them with a font that covers CJK-C?
Another issue is that the name vi-nom is quite confusing. It looks like a lang parameter, but it isn't. Could we change the name to "Nom" or "HanNom"? Kauffner (talk) 18:03, 6 April 2013 (UTC)[reply]
Of course we could change its name, but only if there’s good reason to do so. I chose the name in accordance with the names of similar templates for Chinese that are typically called like {{zh-zhuyin}}, {{zh-trad}} or {{zh-viet}}. IMO template users should read a template’s documentation before they use it. And vi-nom is not a defined locale that could be used with {{lang}} anyway.
As to the HAN NOM fonts: I don’t like them either, and their style seems to be a mere copy of mainland Chinese Sòngtǐ宋体 fonts. However I am reluctant to just drop the HAN NOM fonts. We might insert other font family names between Nom Na Tong and those instead, e.g. Sun-ExtB and MingLiu_HKSCS-ExtB. And Andrew’s BabelStone Han contains 456 of the 4149 Extension C characters as well. --LiliCharlie 20:12, 6 April 2013 (UTC)
Although I have all those fonts installed, I can display the notorious 𫋙/càng character only with HanaMinB. In any case, the CJK-C characters are pretty obscure, likely to be used only in the context of "stuff recently added to Unicode". Take a look at Han unification. I used vi-nom to add Vietnamese characters to the charts. Kauffner (talk) 03:37, 7 April 2013 (UTC)[reply]
I have updated the list of fonts in the template {{vi-nom}}. Please keep me informed if this fixes your display problems. If not I might consider reverting to the old template. --LiliCharlie 15:58, 7 April 2013 (UTC)
I think the problem is that "Nom Na Tong" is at the head of the list in vi-nom, so if installed it is always used, even for CJK-C characters, which it does not cover. A possibility is to create a separate template for CJK-C and CJK-D characters that just lists fonts that support CJK-C and CJK-D, and use that for 𫋙 rather than vi-nom. BabelStone (talk) 16:56, 7 April 2013 (UTC)[reply]
Sounds good. So the new template would only list a few SIP fonts. And the day browser/OS support for CJK-C/D is sufficient it could be redefined as {{vi-nom|{{{1}}}}} and thus become synonymous with {{vi-nom}}. Would {{vi-nom-C-D|...} be an appropriate name for the new template, or is {{vi-nom-CJK-C-D|...} a better choice? --LiliCharlie 17:43, 7 April 2013 (UTC)
The new template for Extensions C and D has been created. I have chosen to call it {{vi-nom-CJK-C-D}} and it has already been applied to the two occurrences of the character 𫋙 in the article Han-Nom. Please report if it works for you. --LiliCharlie 02:51, 8 April 2013 (UTC)
Thanks, that works for me (with HanaMinB installed on my computer). "HAN NOM B" (and HanNom-B?) only accidentally includes 106 CJK-C characters because it put a number of unencoded characters in the reserved code points at the end of the CJK-B block and these later became part of CJK-C with the result that HAN NOM B (and HanNom-B?) has completely the wrong glyphs for CJK-C characters U+2A700 through U+2A769. Therefore, HAN NOM B (and HanNom-B?) should be removed from the template list. BabelStone (talk) 10:59, 8 April 2013 (UTC)[reply]
Glad it works for you. I remember having noticed that HAN NOM B’s encoding is faulty, but that was several years ago, and since I had alternative fonts and never liked and used it I later forgot. — HANNOM-B is the font’s PostScript name. I know that only font family names should be used in CSS, and not PS names, but it’s an old habit of mine to list them too, as this won’t do any harm but might improve someone’s display... --LiliCharlie 20:51, 8 April 2013 (UTC)
Great job! It displays for me too. Perhaps you could shorten the name of the template. After all, this one isn't specific to Vietnam. It could be just CJK-C-D. Kauffner (talk) 14:30, 8 April 2013 (UTC)[reply]
Finally! Gives me the feeling I’ve been helpful. — {{vi-nom-CJK-C-D}}is language specific: Notice that I plan to make it synonymous with {{vi-nom}} when it is no longer needed (see above), and if an expanded version of Nom Na Tong or an equivalent font is available, it will come on top of the template’s font list. All CJKV fonts are locale specific. The Japanese wouldn’t want their character for zen displayed as 禅 instead of 禅 (with ㇔㇒ instead of ㇔㇔㇒), nor do Hong Kongers like to see their window character as 窗 for 窗 (with ㇒㇒㇔ instead of ㇒㇇㇔). If you don’t see the difference use the government-official standard fonts 華康標準宋體=DFSongStd from HK and 全字庫正宋體=TW-Sung from TW; for Kǎitǐ楷體 style I recommend 華康香港標準楷書=DFHKStdKai-B5 and 全字庫正楷體=TW-Kai. — BTW, it’s great that the article Han unification now has Nôm in the comparative table. As my window example showed the Chinese examples should be given by country, as in the Chinese WP, and other information is misleading as well. I hope I’ll find the time to write a versatile JavaScript called Script Display Tester later this month, and then will take care of Han unification. I think I have a good knowledge of local differences in CJKV typography. --LiliCharlie 20:51, 8 April 2013 (UTC)
For many of the examples on the chart, the differences quite trivial. We could remove some of them and focus on those where the differences are more significant. The biggest difference is between the mainland Chinese font and the Taiwanese font. Of course, that's Cold War politics rather than language. One or the other must have decided to create a distinct font so you can use typography to express political loyalty. If we could somehow add a font from the 1920s to the chart, we might have to reinterpret what it means to use "traditional" font. Kauffner (talk) 10:22, 9 April 2013 (UTC)[reply]
Well, Singapore has copied mainland China’s typographical manners for decades, and printed matter from Hong Kong as well as from Malaysia more and more resembles what comes from Běijīng and Shànghǎi, too, so this matter is no longer a battle that’s keeps Cold War alive. — Until ten years ago Taiwanese officials persecuted anyone who dared to publish in simplified characters. That was orthographic Cold War! And that atmosphere certainly had a strong influence on the island’s font scene and Taiwanese art as a whole. Fortunately its rulers have come to reason, and even sanctioned Hànyǔ pīnyīn. Things have become much more relaxed and a little more mixed, and there are now web sites on the mainland like the Buddhist Homeland Shrouded in Mists ;-) that are entirely in traditional characters. To be sure, all this is not intended as a comment on the nature and quality of countries’ political systems, let alone their peoples.
Sometimes the difference between traditional and simplified characters is even more complicated. 薴níng ‘limonene’ has the simplified form 苧; however 苧zhù ‘a type of grass’ is a traditional character which has the simplified form 苎. In this case wrong or no use of zh-hant and zh-hans not only causes an unwanted display, but may have strange effects on translation software, conversion software, etc. Try the conversion of 苧 in both directions with BabelStone’s BabelPad. This is a nice example of the effects of Unicode’s Han unification policy and of the necessity—not only for display—to use zh-hant vs. zh-hans markup for Chinese.
If you are seriously interested in the matter of font display we could try font embedding. For a start I could produce a WOFF font that contains just the two glyphs for 𫋙 and ⿰朝乙, so the font file the browser automatically downloads would be tiny. As you know I already have ⿰朝乙 in SVG format which is easy to convert. This technology has several advantages: it is now supported by all major browsers, so you can be way over 90% sure readers view the characters as intended, and it is a real vector font that doesn’t look as ugly as a magnified pixel image, and matches in size with the other characters. I’m not sure if Wikimedia support uploading web fonts though, but if you are interested I will check. --LiliCharlie 21:53, 9 April 2013 (UTC)
If you want to try, that's certainly fine with me. I was thinking the giàu character might look nicer if we photoshopped the background. But otherwise I'm satisfied with how it looks now. I put the article up for DYK, but it was rejected. It seems to me the writing is well above DYK standard. I'm sure it was IIO's carping that killed the nomination. Guy stalks me everywhere, a vindictive Frenchman with too much time on his hands. Kauffner (talk) 09:27, 10 April 2013 (UTC)[reply]
It was rather rude to reject your DYK nomination without any explanation, but I think the reason would be that the article has to be nominated within 5 days of creation (DYK rules), and it was created on 9th March but only nominated on 19th March (sometimes a little leeway is allowed, but 10 days is too long). Wrt web fonts, I think that might be a good idea, but probably would need wider discussion amongst the community. If we could upload suitably licensed web fonts to Commons and use them to display characters not generally catered for out of the box that would be a great improvement for articles which use obscure scripts and characters. BabelStone (talk) 10:36, 10 April 2013 (UTC)[reply]
Thanks for the hint, Kauffner. I’m not sure if {{Contains Vietnamese text}} should be changed to tell the user to install Nôm fonts, and delete the not yet functional template {{Contains Nom text}} after it has been replaced by {{Contains Vietnamese text}} on all pages, or if it’s better to keep {{Contains Vietnamese text}} as a general browser support warning and write {{Contains Nom text}} as a font specific template. What do you think? Do we need separate templates for these two things? --LiliCharlie 19:35, 6 April 2013 (UTC)
The Vietnamese alphabet displays for Windows 95 and later. It is only Han-Nom that is an issue. So there is no need for two templates. Kauffner (talk) 19:10, 8 April 2013 (UTC)[reply]
Thank you for hosting my fonts. As your website doesn’t seem to recognize files in WOFF format I have now hosted NomWebExtension.woff at http://typefront.com where it is available for embedding in en.WP at http://typefront.com/fonts/825591377.woff.
This is a first test with embedded fonts. The first and last characters 雨 and 没 are only for reference; the two in the middle are our notorious ⿰虫強 at u+2B2D9 (CJK Unified Ideographs Extension C) and ⿰朝乙 at u+F8000 (Supplementary Private Use Area-A). The first line is an attempt at embedding the WOFF font from typefront.com and in the second line I try to embed the corresponding TTF from babelstone.co.uk.
雨𫋙没
雨𫋙没
WP obviously doesn’t allow my style='@font-face {...}' definitions and overwrites them with style="/* insecure input */". This test has failed. --LiliCharlie 01:08, 12 April 2013 (UTC)
Interesting, but perhaps not that surprising. It seems that you would have to get changes made to the MediaWiki software to support web fonts, which I can't imagine would be easy, especially if people have concerns about potential misuse of web fonts for nefarious purposes. BabelStone (talk) 01:49, 12 April 2013 (UTC)[reply]
I don’t dare start a discussion on this topic. First, I am a lover of writing systems, typography and calligraphy rather than a programmer with a highly technical background. And what’s more English is neither my first nor my second language, so I fear that talks might break down because of insufficient linguistic and/or cultural competence on my part. It’s a pity, for so many Wikipedia articles could be drastically improved if only nearly universally supported modern font technology were also supported by MediaWiki and Wikimedia Commons. If you look at HTML/CSS code you will discover that a surprisingly high number of webpages “already” rely on font embedding (i.e. 15 years after its first employment), and as far as I’m aware it works without any security issues that are worth mentioning.
This document (in Vietnamese) says that the Nom Na Tong font is based on characters found in the 1933 edition of a book called Thiền Tông Bản Hạnh (The Origin of Buddhist Meditation) by Thanh Tu Thich. Kauffner (talk) 16:25, 15 April 2013 (UTC)[reply]
Buddhist monasteries all over the Sinosphere are a great source for countless CJKV characters. The monks and nuns kept inventing 漢字 in an effort to render expressions they found in Buddhist texts written in a large number of foreign languages, or to convey the uniqueness and unspeakableness of their mystical experiences. I’m sure that many more characters from Buddhist texts will be added to Unicode over time, but diligent systematic studies are necessary before further proposals can be submitted to the IRG. --LiliCharlie 03:33, 17 April 2013 (UTC)
There is yet another language template for Vietnamese you might want to check out: {{vie}}. On another issue, I adjusted the {{vi-nom}} template and it now seems to work for CJK-C and CJK-D characters as well. Kauffner (talk) 20:52, 8 May 2013 (UTC)[reply]
Thank you for pointing to {{vie}}. To my mind the template could be improved by adding HanaMinA so there is less mixing of different fonts. For example the (Japanese) character u+8217 舗 of the documentation is displayed with PMingLiU although I have Nom Na Tong and all fonts of the HanaMin series installed. Also 城舗胡志明 (with the said Japanese character) for Thành phố Hồ Chí Minh of the template documentation looks strange to me. Shouldn’t that be written 城舖胡志明?
The {{vi-nom}} template had always worked on my system, and {{vi-nom-CJK-C-D}} was created because you had issues with {{vi-nom}} on yours. I have no means of testing if {{vi-nom}} now works on all platforms. If you are not 100% sure {{vi-nom}} works with Extensions C and D on all systems I still recommend using {{vi-nom-CJK-C-D}}. LiliCharlie 06:29, 9 May 2013 (UTC)
It looks like {{vie}} was copied from Japanese Wiki and 城舗胡志明 is "Ho Chi Minh City" in Japanese. This is a bad example since it is a modern name that was never written in Han or Nom -- unless you count Wiki zh-classical, which gives "胡志明市". I copied the font list from {{vi-nom}} to {{vie}}, so the two templates should have the same output now. The use of a separate Vietnam-oriented template for recently added Unicode characters is a kludge, so IMO {{vi-nom}} is the better solution. The {{vi-nom-CJK-C-D}} template can be renamed and presented as a solution for displaying the CJK-C and CJK-D characters in general, since this problem is not specific to Vietnamese.
Yes, I felt that {{vi-nom-CJK-C-D}} was a hack from the very start, and this was the reason I wrote that I wished it to be become synonymous with {{vi-nom}} some day. Yet it seems to have fixed your display problems at one time. (I remember BabelStone’s remark that in a character string an Extension B/C character was not displayed for you because the font on your system was already determined by the surrounding characters, or something to this effect. — Please keep in mind that an isolated character may look different from the very same character within a sequence of characters.)
I closely watched any changes to Han unification and I appreciate your edits very much. — Obvious, though not serious, errors are: the code points for u+9913 餓 and u+997F 饿 are reversed and u+7985 禅/禅 has a traditional character equivalent that is not mentioned, u+79AA 襌. These shortcomings are not fundamental though. — I fail to understand the last sentence of the introduction to the examples: Why on earth is there mention of “non-graphical language tag characters ... for plain text language tagging” if using these tag characters is strongly discouraged?
I am in the process of creating SVG images for all the characters in the tables of Han unification and its equivalents in three or four other WP languages. Whenever available images for the six Unicode CJKV chart (or source) locales will be produced.
Generally speaking I think that the article Han unification (which is about how the Unicode Consortium decided to encode characters) might be improved by closely following the Unicode specifications. Illustrative sample glyphs should be given for the same locales as are given in the Unicode charts (China, Hong Kong, Taiwan, Japan, Korea, Viet Nam), irrespective of language or the traditional vs. simplified character distinction. (N.B.: for the sample characters in the two tables of Han unification I can show you that the government official reference fonts of HK (DFSongStd = 華康標準宋體) and TW (TW-Sung = 全字庫正宋體) have clearly different glyphs [at first sight] for at least 10 characters, even though the fonts that ship with Mr Gates’s Windows are somewhat less divergent.) — To closely follow the Unicode standard also means to talk about semantic variants etc. Please be—or get—prepared to talk about how Unicode handles CJKV characters (which is not the same way as they are traditionally treated in East or West Eurasia).
As I am neither a native nor second language speaker of English I am reluctant to make changes to en.WP. Please go ahead and make the changes I don’t dare make. Together we are strong. LiliCharlie 00:02, 10 May 2013 (UTC)
I fixed the mistakes you mentioned at the top of the post, but I don't really understand what you are proposing lower down. What characters do you want to use? There are 26 characters on "language dependent" chart now, which I think is too many. When the differences are slight, there is no great lost in removing a row altogether. Traditional vs simplified is not a true language dependency anyway. A Japanese vs. Chinese variation is likely to be of wider interest. So I think we could boil it down to 10 or 15 rows. I like the "Zen" character issue you mentioned before. We should be able to do some more with that. That's certainly a better talking point than the "grass" character that gets brought up so much.
I too have an ambitious font project: to get the {{lang-vi}} template to apply the best available fonts for Vietnamese. The first step is a font comparison, which I am doing here. Kauffner (talk) 15:00, 10 May 2013 (UTC)[reply]
That’s right, there is no need for a larger number of sample characters. And yes, 禪/禅/禅 is a nice one that can be elaborated on.
The reason I insist on the zh-HK vs. zh-TW distinction is that some characters that are dis-unified in TW and hence in Unicode get re-unified in HK, in a way of speaking. This is the reverse of what happened to 禅/禅. — To get an impression please go to http://glyph.iso10646hk.net/english/download_001.jsp and download the official Hong Kong ISO 10646 reference font DFSongStd/華康標準宋體, and to http://www.cns11643.gov.tw/AIDB/download.do?name=字型下載 and download the official Taiwanese (general) reference font TW-Sung/全字庫正宋體. Then install them and make them (temporarily or permanently) the fonts your browser uses to display text in the zh-HK and zh-TW locales and then have a look at these characters that are already in the tables of the Han unification article:
兌兑稅税 (zh-HK)
兌兑稅税 (zh-TW)
Actually Hong Kong officials seem to refuse to make the BIG-5 distinction that entered into the Unicode standard but was not judged to be a case of compatibility characters for pre-existing encodings by the IRG, because it doesn’t make sense to the experts from Hong Kong (nor to me, BTW) and because their typographic tradition is much closer to that of Mainland China (and maybe also influenced by the comparatively strong Japanese speaking minority of HK, though this seems less important in this context. — To be sure, what I like to call character “re-unification” is more than just a matter of using different glyphs. Rather it’s a silent but official way of saying: “You BIG-5 encoders and Unicoders have overdone the Han dis-unification thing.”
When I said I wanted to closely follow the Unicode Standard I meant that all Unicode Han Database “fields” that have become necessary by the way the Unicode Consortium decided to handle Han characters deserve mention consideration. At this point the complete list of UniHan fields is: kAccountingNumeric, kBigFive, kCangjie, kCantonese, kCCCII, kCheungBauer, kCheungBauerIndex, kCihaiT, kCNS1986, kCNS1992, kCompatibilityVariant, kCowles, kDaeJaweon, kDefinition, kEACC, kFenn, kFennIndex, kFourCornerCode, kFrequency, kGB0, kGB1, kGB3, kGB5, kGB7, kGB8, kGradeLevel, kGSR, kHangul, kHanYu, kHanyuPinlu, kHanyuPinyin, kHDZRadBreak, kHKGlyph, kHKSCS, kIBMJapan, kIICore, kIRG_GSource, kIRG_HSource, kIRG_JSource, kIRG_KPSource, kIRG_KSource, kIRG_MSource, kIRG_TSource, kIRG_USource, kIRG_VSource, kIRGDaeJaweon, kIRGDaiKanwaZiten, kIRGHanyuDaZidian, kIRGKangXi, kJapaneseKun, kJapaneseOn, kJis0, kJis1, kJIS0213, kKangXi, kKarlgren, kKorean, kKPS0, kKPS1, kKSC0, kKSC1, kLau, kMainlandTelegraph, kMandarin, kMatthews, kMeyerWempe, kMorohashi, kNelson, kOtherNumeric, kPhonetic, kPrimaryNumeric, kPseudoGB1, kRSAdobe_Japan1_6, kRSJapanese, kRSKangXi, kRSKanWa, kRSKorean, kRSUnicode, kSBGY, kSemanticVariant, kSimplifiedVariant, kSpecializedSemanticVariant, kTaiwanTelegraph, kTang, kTotalStrokes, kTraditionalVariant, kVietnamese, kXerox, kXHC1983, and kZVariant.
More especially none of the fields that have “Variant” or “Source” in their names can be omitted if we are really talking about Unicode/UniHan, and not Han characters in general. — Rome wasn’t built in a day, and the article can only be developed by and by, too. Han characters are a vast (actually an open-ended) field of research and contemplation.
For your work on the lang-vi template make sure you don’t forget the fonts that ship with Mac OS, and maybe Linux and Android as well. Richard Ishida has created an overview of non-Latin-Cyrillic-Greek Windows and Mac OS fonts by script, and he updates the list when new versions of these two OS’s are launched. The links given in the notes section at the bottom of his page might serve you as a starting point for finding Vietnamese Mac OS fonts. If you have no access to a Mac/Linux/Android OS you could try to ask a friend/someone to send you screenshots or allow you to use their computer for a couple of minutes. LiliCharlie 09:36, 11 May 2013 (UTC)
No, I haven't been purged or anything like that, but thanks for your concern. I took a trip to the delta for a few days. I come back to find my user page missing and the focus of considerable uproar.
Anyway, let's get back to fonts. I downloaded both the Hong Kong and Taiwanese fonts you mentioned above and I added them to the comparison chart in my sandbox. TW-Sung looks all messed up on Google Chrome, so I would advise against its use on Wikipedia. They throw Unicode and Big5 together, so the font has 113,000 character codes -- the opposite of Han unification.
I didn't notice any display problems with DFSongStd, the HK standard font. In the majority of cases, the HK character is identical to the one in the Taiwanese font. In some cases, DFSongStd uses a hybrid of the mainland and Taiwanese character. On Wiki, zh-HK yields the same font as zh-TW. Has HK always had its own fonts? There was no political motive to create a distinct local font under the British, so why would anyone bother? In any case, they obviously have one now. User:Rjanag maintains the {{lang-zh}} template, so we can ask him make appropriate adjustments.
With the fields, I was thinking that we could have a box on the right that gives three or four of the fields for each character. The fields related to nationality strike me as the most relevant. For example, the reader may interpret a row differently depending on whether the character has a Japanese, Korean or Vietnamese field.
{{lang-vi}} should probably make the font look like it does on a Vietnamese site, with Arial or New Times Roman for the alphabetic script and Nom Na Tong for the Han characters.
The character you were looking for in vain is U+51B7 冷. It’s quite a common one meaning cold (literally and figuratively). Unicode has also encoded a corresponding kZVariant/compatibility character U+F92E.
As regards fonts Hong Kong and Taiwan have different needs since people have to be able to write their own different languages that require different characters — Taiwanese Mǐn Nán vs. Cantonese Yuè. Moreover there are special characters in use for place names and proper names that don’t occur elsewhere. Never forget that even tiny Macao needed 16 characters of their own to be encoded in Unicode, and Singapore contributed 226 own characters. — The names issue sometimes has strange effects: For decades even smaller Mainland Chinese character dictionaries showed the “Japanese-only” character 畑 and defined it as a character used as a Japanese family name or similar. The reason was that Chairman Máo had once met a Japanese who used that character in his name... — For such character borrowings UniHan seems a perfect solution to me.
It should be noted that UniHan unifies characters used 1. in different eras 2. at different places 3. for different languages. — FYI, valid ISO 639-3 codes for Chinese languages are: cdo: Min Dong Chinese; cjy: Jinyu Chinese; cmn: Mandarin Chinese; cpx: Pu-Xian Chinese; czh: Huizhou Chinese; czo: Min Zhong Chinese; gan: Gan Chinese; hak: Hakka Chinese; hsn: Xiang Chinese; ltc: Late Middle Chinese; lzh: Literary Chinese; mnp: Min Bei Chinese; nan: Min Nan Chinese (includes Taiwanese); och: Old Chinese; wuu: Wu Chinese (includes Shanghainese); yue: Yue Chinese (includes Cantonese); zho: Chinese (= ISO 639-1 zh) [macrolanguage that includes cdo, cjy, cmn, cpx, czh, czo, gan, hak, hsn, mnp, nan, wuu, yue]. All these require their own set of characters and may be used at the start of locale codes. — There are also ISO 639-3 codes for older forms of Japanese and Korean, but strangely only vie = ISO 639-1 vi for Vietnamese. I have no idea why.
I very much appreciate your efforts to solve display problems and even show the existing differences between Hong Kong and Taiwanese typographic traditions on your fonts page.
I am almost done with my UniHan SVGs. I have decided to show the characters exactly as they are seen in the Unicode character code chart PDFs (only much enlarged), for up to six IRG sources. I hope I can make a preview page with probably 107 SVGs for 206 Unicode characters available soon. — How do you judge the following sentence linguistically and in content: “The reproduction for purely scientific and informational non-profit purposes of this minimal proportion of the Unicode Character Code Charts which are copyrighted by US based Unicode, Inc. falls within the fair use doctrine of United States copyright law and the fair dealing doctrine and similar doctrines of limitations and exceptions to copyright of other jurisdictions.”? LiliCharlie 23:39, 24 May 2013 (UTC)
I noticed that the character for phở, the famous Vietnamese soup, is in Extension E. It is (⿰米頗) and is No. 06234 in the proposal. Perhaps you could make another svg? Kauffner (talk) 04:43, 23 May 2013 (UTC)[reply]
Nom Character V04-5055.svgLiliCharlie 23:39, 24 May 2013 (UTC)
I put this thing into the Han-Nom chart already, and my friendly stalker put it into the pho article,[1] which was disconcerting but saves me the trouble of having to do it myself. Kauffner (talk) 12:20, 25 May 2013 (UTC)[reply]
If Wikipedia is to be encyclopaedic the article must stay. LiliCharlie 23:39, 24 May 2013 (UTC)
They could get rid of all the Vietnamese terminology that we've been using for years: Han-Nom, chu Han, Han tu, etc. Then Japan would have "kanji", Korea would have "hanja", but Vietnam would have "Chinese characters." I don't know what to tell them. Kauffner (talk) 15:31, 25 May 2013 (UTC)[reply]
How do you judge the following sentence linguistically and in content: “The reproduction for purely scientific and informational non-profit purposes of this minimal proportion of the Unicode Character Code Charts which are copyrighted by US based Unicode, Inc. falls within the fair use doctrine of United States copyright law and the fair dealing doctrine and similar doctrines of limitations and exceptions to copyright of other jurisdictions.”
I count 56 words, so that's a really long sentence. I'll break it down: "This is a minimal portion of the Unicode Character Code Charts, which are copyrighted by US-based Unicode, Inc. Reproduction for scientific and other non-profit purposes falls within the fair use doctrine of United States copyright law, as well as the equivalent doctrines of other jurisdictions.” Kauffner (talk) 12:41, 25 May 2013 (UTC)[reply]
So what do you make of this character: . I got it from Le Chieu Thong, an 18th century king. Is it close enough to 謙 / khiêm or some other character so we can encode it? I found a manuscript of the primary source, a well as a transcription. Where I would I expect to see this character, the transcription has a notation that says "維農貢縣古定社人也". Any idea what that means? Perhaps it says, "This king hated historians, so he used a character in his name that has made it very difficult for anyone to write about him." ☺ (This is a Unicode smiley). Kauffner (talk) 14:07, 25 May 2013 (UTC)[reply]
Hi, regarding this edit, can I asked were you contacted by email by User Kauffner prior to this edit?
(diff | hist) . . Han-Nom; 05:01 . . (+31,522) . . LiliCharlie (talk | contribs) (Undid revision 563384239 by Gaijin42 (talk) — en.WP (being WP’s most international edition) should not make less distinctions than vi.WP and zh.WP (being the WPs most involved in this subject))
Saying nothing about the vi.wp article (since vi.wp didn't have one, it was translated from English at request of User:Kauffner) but looking at zh:汉喃, what does that really say? that 汉 is 汉, and 喃 is 喃. It isn't much of an article is it? And in any case the issue is English. But anyway, the main question is were you contacted by email prior to the edit above. In ictu oculi (talk) 07:02, 9 July 2013 (UTC)[reply]
No, there hasn’t been any contact. NEVER. If you don’t believe me, go and ask the NSA. — Thank you for denying I am capable of making my own decisions. And for implicitly accusing Kauffner, too. Cheers. LiliCharlie 07:26, 9 July 2013 (UTC)
Okay, sorry to have had to ask, but you can understand that with the edit warring to suddenly have someone else who didn't take part in the merge discussion suddenly make the same edit raises an eyebrow. It's a reflection on the problem, not on your good self. Cheers. In ictu oculi (talk) 08:26, 9 July 2013 (UTC)[reply]
I didn’t take part in that discussion because I am an inexperienced Wikipedian who was uncertain about the rules of the game. You will have observed, however, that I contributed to Kauffner’s ambitious article now and then. And if my memory serves me well it was YOU who wrote on the article’s talk page that my comment on the alleged impossibility of teaching Hán-Nôm should be preserved after the merger. Where is it gone? LiliCharlie 09:07, 9 July 2013 (UTC)
Sorry I can't recall the comment, nor did I implement the merge. Off the cuff I can't see why teaching either classical Chinese or demotic Vietnamese would be impossible, but the issue would be is there a printed source saying teaching classical Chinese is impossible, or a printed source saying teaching Vietnamese demotic script would be impossible. If there's a printed source for either of these statements then they could be added to the existing articles. In ictu oculi (talk) 09:16, 9 July 2013 (UTC)[reply]
I’ve found it; it’s here. — Of course any script (i.e. writing system as defined in Peter T. DANIELS & William BRIGHT (1996): The World’s Writing Sytems) can be written, read and therefore taught. LiliCharlie 12:11, 9 July 2013 (UTC)
My link to the still existing Han Nôm talkpage doesn’t seem to work; it gets redirected to Chữ nôm. Is it possible to redirct an article but not its talkpage? LiliCharlie 12:30, 9 July 2013 (UTC)
The article is a redirect to Chữ nôm, but the talk page is still there under it's old name. It's linked from the merge box at the top of talk:Chữ nôm. As for the sentence you were challenging, after you tagged it as needing a citation, Kauffner removed it, and that wasn't changed when it was merged to Chữ nôm.
Hello and welcome to Wikipedia. When you add content to talk pages and Wikipedia pages that have open discussion (but never when editing articles), please be sure to sign your posts. There are two ways to do this. Either:
Add four tildes ( ~~~~ ) at the end of your comment; or
With the cursor positioned at the end of your comment, click on the signature button ( or ) located above the edit window.
This will automatically insert a signature with your username or IP address and the time you posted the comment. This information is necessary to allow other editors to easily see who wrote what and when.
Hi, thanks for your advice on how to edit the sample RP material into the Received Pronunciation article. I'm afraid I got waylaid by some urgent matters and have only now got going on this. I seem to have taken a few wrong turns wrt your advice, but have a sort of working paragraph now in my sandbox. The audio file should not, I'm sure, produce the screen display that comes up when you click on the link, and I'm not sure the transcriptions are shown in the right place. If you have the time to take a look I'd be grateful. RoachPeter (talk) 12:07, 8 December 2013 (UTC)[reply]
Hello, thanks for intervening to help in the matter of copyright status of material on Received Pronunciation. I have left a message for you and Wiereth (well, it's more of a cry for help, actually!) on my own Talk page. RoachPeter (talk) 15:32, 1 January 2014 (UTC)[reply]
What I hear is a diphthong of [aɪ̯] type. (Historically in French there was a rule /aj/→/ɛ/, which seems “reversed” here.) – C’est un locuteur québécois, n’est-ce pas? —LiliCharlie (talk) 16:36, 8 January 2014 (UTC)[reply]
If this is my choice I’d say it’s closer to [aɪ̯] than to [eɪ̯]. — Do you know this concise description of the phonetics of French? (The section “L'accent canadien (Québec)” starts on page 28 and the one called “Variantes du canadien” on p. 38; have a look at the illustrations of the vowels and compare them to one another and to other accents. More material on this so-called “natural phonetics” by Luciano Canepari is available for download here.) LiliCharlie (talk) 12:41, 9 January 2014 (UTC)[reply]
Yes. Please note that if you want narrow “impressionistic” transcriptions your transcribers must all be trained in the same tradition, otherwise they are bound to diverge wildly. — I want you to create a user account and discuss matters on your own talk page. Et si tes connaissances de l’anglais ne suffisent pas à prendre part à une telle discussion on peut délibérer sur ta page de discussion de la Wikipédia française. (Ma langue maternelle est ni celle de Molière ni celle de Shakespeare, alors padonne-moi quelques petites erreurs.) LiliCharlie (talk) 06:26, 11 January 2014 (UTC)[reply]
gerne doch! Deine Transkription war total korrekt. In der Tat habe ich als Norddeutscher Das /r/ in Bernd vokalisiert.
Ich finde, das ist aber auch richtig für Standarddeutsch.
Tja, mit dem J. : es ist in jedem Fall die korrekte Transkription im Standarddeutschen . Gesprochen wird es im deutschen in der Tat seltener . Ich finde das J. Für mich als Wissenschaftler sehr wichtig , da ich damit von anderen bernd Krögers besser unterscheidbar bin.
Nochmals vielen Dank für deine Transkription. Bernd Bkroeger (talk) 20:38, 19 January 2014 (UTC)[reply]
I'm gonna get accused of polling maybe, but I quote you in this CfD. I think your comments about national sentiment and expertise and so on were useful; but whether people listen to me or not because I pick apart their faulty logics/perceptions/information at length is dubious; I'm made the issue, as usual, rather than the problem created by someone else who refuses to acknowledge they caused a problem..... it's a long story, and I come off as the bad guy for criticizing someone else's very bad idea and also their abuse of process....how can you criticize a bad idea if not by criticizing it??Skookum1 (talk) 08:14, 21 February 2014 (UTC)[reply]
Hi there. I saw your comment at module talk ZH regarding the small size of Chinese fonts. If you add the following line to your vector.css file under preferences, you can make template wrapped Chinese text in articles appear how you wish by tweaking the colour/font/size:
Oh, I already have a solution for that if proper language markup is used (e.g. {{zh}} or {{lang|zh}} etc.). It's a mix of browser preferences and Stylish which is also CSS based, but not restricted to en.WP. Despite a larger font size I use line-height: 100% for CJK characters, which is enough as I don't expect diacritics for CJK, except maybe for Zhuyin. It is extremely nice of you to care about an old person's eyesight and display problems. Thanks a lot. Love —LiliCharlie (talk) 20:09, 25 February 2016 (UTC)[reply]
Just a heads-up that you placed a warning on my talkpage for "vandalism" to Chinese language, though the actual edit was by Prisencolin and that too was a mistaken blanking.
BTW, in future, it's generally inadvisable to jump to level 3 user warnings such as {{uw-vandalism3}} right off the bat. Those should only be used as a first warning in instances of clear vandalistic or bad-faith editing, which this was obviously not. Satellizer(´ ・ ω ・ `)06:29, 26 March 2016 (UTC)[reply]
Their is no misconception about no accent. The midwest has many. And many different kinds. I never got this accentless style of stuff and see no reason why it should be included, considering the page itself links to the numerous accents on that page. And I really don't even see what this has to do with general american at all. General American isn't the midwest at all. Chrishayes00003 (talk) 16:01, 6 April 2016 (UTC)[reply]
There exists a widespread notion that a Midwest accent is close to or even identical with GA. (See for instance the Urban Dictionary: "General American is also known as the Midwestern Standard..." or dialect blog: "In the narrowest sense, the General American “heartland” is found in a tiny chunk of the midwest.") — Not everybody in the English speaking world knows as much about the American Midwest and its multitude of accents as you do, so it's helpful for lots of users to keep this sourced statement. Love —LiliCharlie (talk) 17:38, 6 April 2016 (UTC)[reply]
What does that have to do with the page though? And it was already stated the exactness is not known on the page. I don't get what this has to do with the midwest at all. Chrishayes00003 (talk) 18:14, 6 April 2016 (UTC)[reply]
Nobody is. Wikipedia is more like a collection of scientific views, conflicting or not. But they should all be reliably sourced. You are welcome to add other scientific views if you can cite such sources. Love —LiliCharlie (talk) 19:05, 6 April 2016 (UTC)[reply]
And what I want to do is remove elements that have nothing to do with GA. It's needless spam. It's not the midwest. And adding how other midwesterners sound contributes nothing to the page. It's already stated within the article page that it has no traceable origins. That is all that needs to be said. Not any of this other useless stuffChrishayes00003 (talk) 17:18, 8 April 2016 (UTC)[reply]
Shouldn't it be 11.5 millions of people instead of 11,500 millions or 11.5 billion of people speaking Japanese as a second language? I really doubt that there are 11.5 billion of people speaking Japanese as a second language in a wold of 7.5 billion of people.--Christophe Hendrickx (talk) 19:24, 6 April 2016 (UTC)[reply]
No, it's only eleven thousand five hundred (or 0.0115 million) L2 speakers. That's why they don't change the total, which is expressed in millions. Love —LiliCharlie (talk) 19:32, 6 April 2016 (UTC)[reply]
I see, then it should be written 0.0115 million as the number of speakers is always expressed in millions for all other languages, and if L2 speakers is sorted in an descending way, Japanese does not appear at a first place. Love,--Christophe Hendrickx (talk) 13:00, 7 April 2016 (UTC)[reply]
Hello, LiliCharlie. You have new messages at Talk:World language. You can remove this notice at any time by removing the {{Talkback}} or {{Tb}} template.
Hello, LiliCharlie. You have new messages at Talk:World language. You can remove this notice at any time by removing the {{Talkback}} or {{Tb}} template.
Why are you blatantly ignoring my responses on the talk page? If you don't want to be involved in the discussion then just say so. I can see that your replying to everyone else's messages on other talk pages but you're just ignoring mine, don't you think I deserve an explanation for your sudden disappearance? I can see you're still active on Wikipedia. (137.147.52.163 (talk) 13:49, 6 May 2016 (UTC))[reply]
I'm not sure whether you didn't see this message which is hard to believe or if it was true that you didn't but I'm going to "ping" you so you see this message, @LiliCharlie:. If you don't want to be involved in the discussion you can say you're not interested so I don't need to keep on checking back to see if you've replied or not. (121.214.104.174 (talk) 04:04, 7 May 2016 (UTC))[reply]
Thanks for replying. Well I am not a different person @LiliCharlie:, if you look at the geolocation of my IP address it locates to Victoria, Australia each time, I am not a different person, I am the same user it's just that my IP address always changes every few days and there are users on Wikipedia who I have mentioned this to in order for them to know that they're talking to the same person when I'm talking with them on talk pages. I should've have told you that my IP address always changes but I thought the problem might be resolved in a few days and not a week so I didn't mention it. If you want to check my geolocation there is a link at the bottom of each user page. (121.214.104.174 (talk) 06:07, 7 May 2016 (UTC))[reply]
Hello @LiliCharlie:, could you please stop ignoring my messages I told you that I am the same person. It's absurd to believe that a different IP user would come directly to the World language talk page and leave messages when registered Wikipedia users don't even frequent that page often. I am the same user and I have told you that I geolocate to Victoria, Australia so could you please stop ignoring me, you are being extremely rude. (120.144.46.18 (talk) 00:38, 8 May 2016 (UTC))[reply]
Hello @LiliCharlie:, just so you know I thought the way you treated me was quite unfair and rude. I gave you an explanation but you did not give me a reply. I hope you don't treat other users the same way you did to me in the future. (121.214.149.4 (talk) 09:16, 9 May 2016 (UTC))[reply]
Based on Unicode allocation and it's size ß is an uppercase letter, much like Ð and Þ. It is common to see the letter ß in all caps, especially on sport jerseys (See KIEßLING).
In fact, it does not look strange if the letter 'große' is capitalized to 'GROßE.'
No, ß is lowercase and its uppercase counterpart is ẞ. 'große' should actually be capitalised as 'GROSSE' and less commonly (unofficially and strongly criticised) as 'GROẞE', not 'GROßE'. Love —LiliCharlie (talk) 20:51, 2 August 2016 (UTC)[reply]
P.S.: Here is a scan from an English document of 1586 in which the words witness, assuring, thankfulness, goodness and blessings are written as witneße, aßuring, thankfulneße, goodneße and bleßings. (The scan is from this blog.) As you see ß is merely a ligature of ss. Love —LiliCharlie (talk) 21:08, 2 August 2016 (UTC)[reply]
Hello, LiliCharlie. Voting in the 2016 Arbitration Committee elections is open from Monday, 00:00, 21 November through Sunday, 23:59, 4 December to all unblocked users who have registered an account before Wednesday, 00:00, 28 October 2016 and have made at least 150 mainspace edits before Sunday, 00:00, 1 November 2016.
The Arbitration Committee is the panel of editors responsible for conducting the Wikipedia arbitration process. It has the authority to impose binding solutions to disputes between editors, primarily for serious conduct disputes the community has been unable to resolve. This includes the authority to impose site bans, topic bans, editing restrictions, and other measures needed to maintain our editing environment. The arbitration policy describes the Committee's roles and responsibilities in greater detail.
Hello, I've looked at the links that you provided from both the Hong Kong and Macau governments regarding official language policy in the two territories. However, their constitutions only provide Chinese (ambiguously mentioned) as an official language alongside their historic colonial languages. In practice, Cantonese is the de facto working language of the government and Mandarin is hardly ever used, only when officials from the Beijing government are involved, hence when simultaneous interpretation in Mandarin is used. Having lived in Hong Kong and visited Macau multiple times, Mandarin is not as omnipresent as you'd expect or want it to be much to the CCP's dismay.
When official emergency announcements (not routine) are provided on transit, media, etc. in Chinese, Cantonese is the only variant used. Under the one country, two systems policy, Chinese equates to Cantonese in these territories (although recent broken promises by China prove to be a challenge). Therefore, Mandarin has a position similar to what Spanish has in the U.S. or French in the Canadian province of Ontario, a minority language that's provided due to the large number of users present in the territories but not official, although in this case, visitors rather than residents. -- User:Moalli (talk) -- 08:19, 9 January 2017 (UTC)[reply]
Edit: I'd like to add that government media in Hong Kong (RTHK) and Macau (TDM) have their free to air Chinese networks in Cantonese and their primary Chinese education curriculum in Cantonese. A link from the HSK, the official Mandarin standardized test sponsored by the Chinese government, also identifies Cantonese as the spoken form of Chinese in these territories [3]. Give this ambiguity in the Basic Laws, it'd make just as much sense to add Shanghainese or Hokkien as official languages since they fall under the "Chinese language" umbrella. -- User:Moalli (talk) -- 09:00, 9 January 2017 (UTC)[reply]
This is indeed a strange definition of official language, which has nothing to do with a majority of people who speak a certain vernacular, nor with schooling or the media, but a lot with certificates, forms and other documents issued by and used in governmental offices — hence the word official. Even the laws in HK and MO are laid down in Standard Chinese (plus English and Portuguese respectively).
Oh, okay I totally understand where you're going now. Yes, official documents in the two regions are laid down in standard Chinese, but it refers to standard written Chinese rather than a specific spoken vernacular. Makes this ambiguity even more confusing. While Cantonese itself does have a colloquial written form, it has not been completely standardized and hence, the written form is standard vernacular written Chinese, which coincidentally matches with Putonghua perfectly. Cantonese speakers still read in their own variant with these characters, although it will sound very formal. In that case, might a suggestion be to still remove the two countries from the spoken Standard Chinese infobox but mention their use in inter-governmental affairs with Beijing using the sources that you have provided? -- Moalli (talk) 05:18, 10 January 2017 (UTC)[reply]
Actually, it seems that it does. Again, there is a difference between spoken 'standard' Chinese as defined by the PRC (Putonghua) and standard written Chinese (not spoken) that is used by speakers of any Chinese variant and on official HK/Macau documents. There was even a debate on the talk page about defining what standard Chinese vs Mandarin is when regarding this article. Initially, these two territories were excluded from the infobox for a reason until someone with 'Marxist' in his username decided to tag them on it. In order to provide a factual and neutral POV, it would be best to only mention the territories in the body with the sources since they the language isn't de jure or even de facto official as their Basic Laws leave it to ambiguity. -- Moalli (talk) 02:00, 11 January 2017 (UTC)[reply]
The main article links to written Chinese, which definitely is not the same as spoken language. From article: The writing system for almost all the varieties of Chinese is based on a set of written logograms that has been passed down with little change for more than two thousand years. Each of these varieties of Chinese has developed some new words during this time, words for which there are no matching characters in the original set. It does not mention the role of Putonghua at all. Any variant of Chinese is written using this system, which just happens to match how standard Chinese is spoken. However, thank you for putting this to debate on the article page. -- Moalli (talk) 02:14, 12 January 2017 (UTC)[reply]
Thanks, but the major issue is that the Spanish article material copied is sourced to a book published by SAIS, the Scientific Atlantology International Society. Doug Wellertalk10:04, 14 January 2017 (UTC)[reply]
Hello. It seems that User:向日葵的夏天 has made certain changes that brought the transcription at Standard Chinese phonology and pinyin back to the complicated old transcription and away from Duanmu, Lin and Lee & Zee. Do you think we should keep his changes? I've avoided reverting further to prevent an edit war.--Officer781 (talk) 00:50, 5 February 2017 (UTC)[reply]
Hi Officer781, what I want is 1. a uniform transcription in all en.WP articles that 2. conforms to IPA usage.
"4 The construction and use of the IPA are guided by the following principles:
(a) When two sounds occurring in a given language are employed for distinguishing one word from another, they should wherever possible be represented by two distinct symbols without diacritics. Ordinary roman letters should be used as far as practicable, but recourse must be had to other symbols when the roman alphabet is inadequate."
It seems the transcription system 向日葵的夏天 has introduced constantly violates IPA Principle 4 (a) since neither the diacritics nor some special non-roman letters are necessary. Love —LiliCharlie (talk) 13:51, 5 February 2017 (UTC)[reply]
Hej LiliCharlie! Concerning this revert and the message you left on anonymous' talk page: wnen I look at the image, the word reads utilißimae. Not exactly what anonymous had written, but also not what you reverted to. Richard09:49, 23 February 2017 (UTC)[reply]
Sorry, I just read the file name without actually scrolling down to the image so I thought the intended word was ultißimae “the very last ones (feminine).” Thank you for renaming the file. Love —LiliCharlie (talk) 12:55, 23 February 2017 (UTC)[reply]
Hello ! I just can see that you are among the last contributors to our German orthography article. I find it wrong , to state that letters as Ä, Ö and Ü are considered "special" in the perspective of that article. I have not removed anything, but added. I think it's polite to alert you , since I can see that the last changes is a year old. I'm not looking for any warring, but am looking for the truth, including sources. Cheers ! Boeing720 (talk) 00:58, 13 March 2017 (UTC)[reply]
Can you give more evidence about the deletion of my edit in "CJK Unified Ideographs"?
You said that U+2011E 𠄞 is a variant version of 上, and is not equivalent to U+4E8C 二. Can you give any link or extra examples to explain that? -- Albert Micah Hang (Talk) 11:06 Beijing Time (UTF+8), May 29th, 2017 —Preceding undated comment added 03:05, 29 May 2017 (UTC)[reply]
Hi LiliCharlie, I have looked at your comment and seen the links you give. In these links, they are the same. HOWEVER, I have searched a couple of other websites that writes the radical 2 as 丄, like [4] and [5], and their shape are NOT the same as yours. Albert Micah Hang (talk) 00:08, 30 May 2017 (UTC)[reply]
Hi Albert Micah Hang, and thank you for your interesting links. My software version of the Shuowen dictionary which aims at reproducing the original text by 許慎 has 𠄞shàng as radical 2, and these are the 10 characters and variant characters grouped together under this radical:
《說文解字‧注》 by 段玉裁 is cited as the source for this enumeration of characters which correspond to the more "modern" Hàn characters 𠄞、丄(上)、帝、𢂇、㫄(旁)、𣃟、𣃙、雱、𠄟、丅(下).
In ancient times the two strokes of the character 二èr were of equal length, but later the upper stroke became shorter than the lower one leading to confusion with 𠄞shàng. Maybe the reason that in later Shuowen editions 丄shàng (the second character of my illustration) was sometimes or even usually taken to represent radical 2 was to avoid this confusion.
Anyway there is no chance that at the time the CJK Unified Ideographs Extension B block was added to Unicode in March 2001 someone thought the character 二èr was still missing from Unicode. It had already been a Unicode character since June 1992, of course. And it is also not conceivable that all the reviewers of the CJK Unified Ideographs Extension B proposal confused this extremely simple two-stroke character with any other character. It is clear that 𠄞 (U+2011E) was intended for something else, namely shàng, and this is the way Chinese researchers and dictionary makers use this Unicode character. Love —LiliCharlie (talk) 17:01, 30 May 2017 (UTC)[reply]
Thanks for deletion about Putonghua, but You would better write me first, so I would redress my own error.
Hello, LiliCharlie. Voting in the 2017 Arbitration Committee elections is now open until 23.59 on Sunday, 10 December. All users who registered an account before Saturday, 28 October 2017, made at least 150 mainspace edits before Wednesday, 1 November 2017 and are not currently blocked are eligible to vote. Users with alternate accounts may only vote once.
The Arbitration Committee is the panel of editors responsible for conducting the Wikipedia arbitration process. It has the authority to impose binding solutions to disputes between editors, primarily for serious conduct disputes the community has been unable to resolve. This includes the authority to impose site bans, topic bans, editing restrictions, and other measures needed to maintain our editing environment. The arbitration policy describes the Committee's roles and responsibilities in greater detail.
It is important than Zhuang characters, or Sawmdip, be supported. Zhuang characters like chữ nôm are use CJKV ideographs to write a non Chinese language for hundreds of years. In Unicode 10 over one thousand Zhuang characters were added. Wikipedia uses Unicode when characters are in Unicode for text. Images of characters in text should be restricted to characters not curremtly in Unicode. Happy to work with you or others on how to solve problems with respect to Zhuang Characters on wikipedia pages.Johnkn63 (talk) 05:03, 30 January 2018 (UTC)[reply]
Thank you for pointing out the need to update the Help:Multilingual support (East Asian) page. I have now updated this. File:Universal Declaration of Human Rights Zhuang Sawndip.png was produced about a decade before Unicode 10 and as such does not show the progress that has been made. File:Universal Declaration of Human Rights Zhuang Sawndip Traditional variant.jpg was made by transposing the characters in the former file, it contains characters I have not seen in any Zhuang document. A character not displaying tells a person they need to install another font, which is not a bad thing. Whilst many more Zhuang characters should be added to Unicode (around a further 1,700 have been submitted to IRG already). The number of chữ nôm characters submitted to IRG last year was twice that of Zhuang characters but we do not say replace encoded chữ nôm with images.Similarly we should support encoded Zhuang characters. Johnkn63 (talk) 05:28, 1 February 2018 (UTC)[reply]
Just FYI, the <strike> element hasn't existed in HTML for a long time. It's <s> now. Using the long form triggers our HTML "lint" cleanup filters, and such. I.e., it's stuff we'll need to cleanup later as we migrate to HTML5. Happily, the valid version is shorter and more convenient. The <del> element also works, for semantic difference from <ins>. — SMcCandlish☏¢ 😼 01:18, 7 July 2018 (UTC)[reply]
Hi! I understand mandarin is a branch of Chinese. And the branchese of mandarin (Putonghua, Taiwan Guoyu, Singaporean/Malaysian Huayu) is implied by using the single term without annotation. As Spanish is not being noted as including Chilean, Mexican, Iberian branches. LUMINR (talk) 11:18, 15 November 2018 (UTC)[reply]
Thank you for clearifying :) Is there a common term for the mutually intelligible, what general people think when they hear "Mandarin" ? LUMINR (talk) 12:12, 15 November 2018 (UTC)[reply]
Hello, LiliCharlie. Voting in the 2018 Arbitration Committee elections is now open until 23.59 on Sunday, 3 December. All users who registered an account before Sunday, 28 October 2018, made at least 150 mainspace edits before Thursday, 1 November 2018 and are not currently blocked are eligible to vote. Users with alternate accounts may only vote once.
The Arbitration Committee is the panel of editors responsible for conducting the Wikipedia arbitration process. It has the authority to impose binding solutions to disputes between editors, primarily for serious conduct disputes the community has been unable to resolve. This includes the authority to impose site bans, topic bans, editing restrictions, and other measures needed to maintain our editing environment. The arbitration policy describes the Committee's roles and responsibilities in greater detail.
Thank you for reverting unlogged IPA editor's vandalisms in Help:IPA/Italian! Would you like to join a discussion I've opened in the Linguistics talk? Iuscaogdan (talk) 19:02, 12 January 2019 (UTC)[reply]
On the -bğ combination: unfortunately, I can not upload the files with this elements, but it is possible to find some maps in free access. I've seen at least 3 maps of different periods (19th century, mid-50s and mid-90s with such an abbreviation for -burg). That is, this is a common practice. Is it enough for the article? 83.149.240.100 (talk) 15:04, 8 February 2019 (UTC)[reply]
No, that's original research which Wikipedia articles must not contain. We don't create news and report things that experts on the subject don't confirm. — The subject here is the institutionally regulated German orthography, and the breve is not part of the inventory of symbols that the legally competent institution recognises as belonging to German orthography (Greek orthós "correct" & gráphein "to write"). Love —LiliCharlie (talk) 15:31, 8 February 2019 (UTC)[reply]
Here is an example with an interletter breve: Saarb˘g, Gusenb˘g, Freudenb˘g. I've found this map today, in the W-Media. It's only one of them... I can suspect that this abbreviation derivates from the tradition of written u with a breve-like symbol. [1]83.149.240.100 (talk) 15:34, 8 February 2019 (UTC)[reply]
There are some things, that (maybe) weren't mentioned in Duden an so on. I'll try to find them. But if the thing exists during some long period, can we say that it's an original research? If it is not a part of orthography, were should we place this piece of information on the writing system? 83.149.240.100 (talk) 15:38, 8 February 2019 (UTC)[reply]
A cartographic representation of words is not the same thing as their orthographic representation.
As an occasional user of Sütterlin I see no relation between Kurrentschrift's graphic representation of u and the breve. In Kurrentschrift the ˘-like shape is part of the basic letter u itself, not a diacritic that modifies a letter. This letter shape doesn't alter the sequence of orthographic symbols.
As an occasional user of Kurrent I see some relation, because breve is used to make the contrast between u and n visible: it's a significant part of letter used to distinguish two different graphemes. 83.149.240.100 (talk) 18:00, 8 February 2019 (UTC)[reply]
Hello LiliCharlie,
Thank you for editing the page List of languages by number of native speakers.
I looked at the number and couldn't find a solid source. Can you organize somehow that all are coming one source?
If you haven't added a source. please do so as soon as possible.
I'd like to work together with you on phonology to make the introduction reflect content of the second paragraph. At the moment the introduction contradicts the second paragraph. — Preceding unsigned comment added by Kelly222 (talk • contribs) 05:50, 12 March 2019 (UTC)[reply]
Where it says, "Khari Boli (Dehlavi, Kauravi, Khadi Boli, Khari, Khariboli, Vernacular Hindustani). Formal vocabulary borrowed from Sanskrit, de-Persianized, de-Arabicized. Literary Hindi, or Hindi-Urdu, has 4 varieties: Hindi (High Hindi, Nagari Hindi, Literary Hindi, standard Hindi); Urdu [urd]; Dakhini; Rekhta. Hindustani, though not listed separately in India, refers here to the unofficial lingua franca of northwest India. Has a lexical mixture in varying proportions of Hindi (vocabulary derived from Sanskrit) and Urdu (vocabulary derived from Persian or Arabic)."
LiliCharlie -
First, I would like to thank you for uploading my map into WikiCommons and making it easily accessible from the "World Languages" article.
Hey- I saw you deleted the sentence about the "semi-simplifed" form of the word 'Taiwan'. There are some assertions made in that same paragraph that are given no citation, so I would invite you (as a person that deletes uncited material) to take a second look at that paragraph and delete some more if you are interested. If it were me, I would probably just keep the whole paragraph, which I generally agree with, but that's because I don't really know how to pick apart what really needs citation and what kind of doesn't. Geographyinitiative (talk) 08:38, 13 May 2019 (UTC)[reply]
Hi. Could you replace the vowel chart on User_talk:JackintheBox#NZ_English_dress_vowel with [6]? I've replaced it on New Zealand English phonology and on Asturian and Spanish Wikipedias and I'm about to make a delete request on Commons. The chart is not only unreliable (they don't cite sources, /e/ is too low on it, it shows /ɵː/ and /ʉː/ as too close to each other and the corresponding diphthong charts based on the same source show /æʊ/ and /ɐʉ/ as [æɔ] and [ɑɵ], which isn't supported by the literature), but it's actually been deleted from the site sometime (I guess a month or two) ago, along with the diphthong chart.
Hi there, LiliCharlie! I don't think we've ever crossed paths. I'm KyleJoan. Please to make your acquaintance! I'm writing because I saw that you contributed to this thread discussing the sorting of a list involving an American person with a surname of French origin. This very discussion is still active over at Talk:The Real Housewives of New York City, and I would love for you to chime in if you would be so kind. Thank you very much, and have a wonderful rest of your week! KyleJoantalk05:46, 7 August 2019 (UTC)[reply]
@Paradise Chronicle: In the infobox of article German language this appears under the "Ethnicity" header, so Italians would mean ethnic Italians, not people having Italian citizenship or nationality. Also note that Italy already appears three times in the infobox: implicitly as "Region: Worldwide", and explicitly as "Official language in: 3 dependencies: South Tyrol (Italy)" as well as "Recognised minority language in: 11 countries: Italy".
German-speaking South Tiroleans are mentioned in the last sentence of the introduction to article Austrians as a "closely related" but separate ethnic group; the article's infobox mentions only 16,331 Austrians in Italy. This means that according to en.WP standards South Tiroleans should probably be added to the list of ethnicities in the German language infobox. You are invited to do this job. — Do you know someone who is able to start a separate article South Tyroleans (which is currently a redirect to South Tyrol) about the German-speaking ethnic group (as opposed to the Italian- and Ladin-speaking ethnicities of the autonomous province)? Love —LiliCharlie (talk) 23:10, 31 August 2019 (UTC)[reply]
Yes, I have seen this. I just have been to Switzerland and noticed there they don't speak German in their free time and the German tourists to switzerland usually also don't understand the Swiss people speaking swiss. But In South Tyrol they do speak German in their free time and the germans do understand them. This were my thoughts why I included Italy. But I have also understood it is not an official language from a country in Italy but only of a dependency, and therefore it is ok for me, like it is now. All the best. Paradise Chronicle (talk) 06:15, 1 September 2019 (UTC)[reply]
The Arbitration Committee is the panel of editors responsible for conducting the Wikipedia arbitration process. It has the authority to impose binding solutions to disputes between editors, primarily for serious conduct disputes the community has been unable to resolve. This includes the authority to impose site bans, topic bans, editing restrictions, and other measures needed to maintain our editing environment. The arbitration policy describes the Committee's roles and responsibilities in greater detail.
Google Code-In, Google-organized contest in which the Wikimedia Foundation participates, starts in a few weeks. This contest is about taking high school students into the world of opensource. I'm sending you this message because you recently edited a documentation page at the English Wikipedia.
I would like to ask you to take part in Google Code-In as a mentor. That would mean to prepare at least one task (it can be documentation related, or something else - the other categories are Code, Design, Quality Assurance and Outreach) for the participants, and help the student to complete it. Please sign up at the contest page and send us your Google account address to google-code-in-admins@lists.wikimedia.org, so we can invite you in!
From my own experience, Google Code-In can be fun, you can make several new friends, attract new people to your wiki and make them part of your community.
If you have any questions, please let us know at google-code-in-admins@lists.wikimedia.org.
Hey. Did we ever decide how to transcribe T1 vs T2? E.g. maybe a circumflex for T1 and either just a stress mark or some other tonal diacritic, maybe a grave, for T2, like [zɛ̂i] (T1) vs [zɛ̀i] (T2), or [ˈzɛ̂i] vs [ˈzɛi]. — kwami (talk) 22:26, 12 December 2019 (UTC)[reply]
Good question. Special diacritics for both pitch accents are traditionally used in orthography-based Serbo-Croatioan linguistic works (and are conflated with marking vowel and syllabic liquid length), whereas one of the two pitch accents of Swedish-Norwegian is viewed as the unmarked form and traditionally has no special symbol in phonemic transcriptions. I prefer the latter choice, unless someone convinces me that two dedicated pitch-accent symbols are genuinely helpful for our users. Love —LiliCharlie (talk) 01:15, 13 December 2019 (UTC)[reply]
Hello LiliCharlie, may you be surrounded by peace, success and happiness on this seasonal occasion. Spread the WikiLove by wishing another user a Merry Christmas and a Happy New Year, whether it be someone you have had disagreements with in the past, a good friend, or just some random person. Sending you heartfelt and warm greetings for Christmas and New Year 2020. Happy editing, JACKINTHEBOX • TALK08:17, 23 December 2019 (UTC)[reply]
@Jusjih: All right, I see you've made the changes to ISO 3166-1, ISO 3166-2:CN, and ISO 3166-2:TW. Strictly speaking however, only the first two of those articles are about Taiwan as an entity, namely ISO 3166-1 country code TW, and ISO 3166-2 country subdivision code CN-TW. Please note that the topic of article ISO 3166-2:TW is not Taiwan as a whole but rather its subdivisions. Also note that the ISO 3166-2 subdivisions TW-KIN designating Kinmen, and TW-LIE designating Lienchiang refer to territories that the PRC does not recognize as being part of their hypothetical Taiwan Province, but part of Fujian Province. In other words the territorial scope of ISO 3166-1 TW is one that only the ROC approves of, whereas the PRC contadicts this way of subdividing Taiwan, no matter what designation ISO 3166-1 code TW is given. Going a step further this means that if you start discussing disputes in ISO 3166-2:TW it would be fair and appropriate to mention that dispute as well. See also Wikipedia:Neutral point of view. Love —LiliCharlie (talk) 12:32, 30 January 2020 (UTC)[reply]
Kinmen and Matsu were omitted from ISO 3166-2:TW as evidenced in ISO 3166-2 Newsletter I-4 (2002-12-10). They were added on 2015-11-27. Added your requested dispute.--Jusjih (talk) 00:38, 31 January 2020 (UTC)[reply]
Carefully read https://www.iso.org/obp/ui/#iso:code:3166:TW to see under "Additional information": "Administrative language(s) alpha-2: zh; Administrative language(s) alpha-3: zho; Local short name: Taiwan". Be bold but not reckless. [8] Want me to upload cropped screenshots of that page to better explain the story? Neutral point of view may mean that all ISO 3166 pages should be politically neutralized.--Jusjih (talk) 04:03, 3 February 2020 (UTC)[reply]
Hello there! Thank you for your work. I was wondering if you can add a language to the lists, or the lists are from other sources. (The language I am talking about is Berber "Tamazight", the native language of North Africa. Kamaqdouf (talk) 19:33, 29 February 2020 (UTC)[reply]
My reasons why my edit is not vandalism is that the edit I did shows that the transcription of the phoneme ʌ to ɐ was done to provide accurate information that corresponds to the transcription of English in IPA format. Although the Lua programming language does not show this, my transcription is strongly valid because the way we pronounce words normally transcribed with the vowel ʌ sounds a lot closer to the vowel ɐ. Another reason why my edit is not vandalism because the page Help:IPA/English also shows that some dictionaries transcribe ɐ as ʌ and other pieces of evidence that show that ʌ might not be an accurate transcription when it comes to the pronunciation of words like cut, runt, shrug, etc. Love—(User talk:Jarabalistic Woofenmoton746) 19:03, 17 March 2020 (UTC)[reply]
ISO 3166-2 I read the page, sorry, I put it like the four countries in one on the Uk article. The article says 3 nations, which I didn't find on the link, is that somewhere else? 80.233.32.213 (talk) 20:08, 2 May 2020 (UTC)[reply]
Hi. Thanks for your help.
This is my concern. I feel that the first sentence should tell us specifically what phonetics is. The average person reading the Phonology page and the Phonetics page would think they are the same thing, based on the first sentences:
"Phonology is a branch of linguistics concerned with the systematic organization of sounds in spoken languages..."
"Phonetics is a branch of linguistics that studies the sounds of human speech..."
They sound the same to me.
I suggest you amend the first sentence using the information in the second paragraph. So, it would start with:
Phonetics is a branch of linguistics that broadly deals with two aspects of human speech: production—the ways humans make sounds—and perception—the way speech is understood. In the case of sign languages, the equivalent aspects of sign would apply.
OR, even better:
Phonetics is a branch of linguistics that broadly deals with two aspects of human speech: the ways humans make speech sounds, and the way speech is understood. In the case of sign languages, the equivalent aspects of sign would apply.
The second paragraph can be changed a little to avoid repetition.
The Phonology page should change to. I suggest:
Phonology is a branch of linguistics concerned with the systematic organization of sounds (i.e. the patterns) in human languages; including phonetics, the ways humans make speech sounds and the way speech is understood. Cheers. John (talk) 20:31, 10 June 2020 (UTC)[reply]
I see you reverted my edit on Flemish. If you consult File:BelgieGemeenschappenkaart.svg, you will see that the summary notes the color as "gold" and "golden", not as "olive green", which is a completely different color. I would appreciate a compromise that would be suitable; that color does not look olive green to me at all.
Hi LiliCharlie, I really appreciate your adding color boxes. I think that is the most suitable solution. The colors used in the maps were a bit odd. Thank you! The Obento Musubi (talk) 01:16, 19 July 2020 (UTC)[reply]
Hi there LiliCharlie, I think this may be one of those black/blue or gold/white dress situations. This website describes #A0A000 as "Dark yellow (olive tone)", and this website describes #A0A000 as "Citrus", and this website describes the color as "a medium dark shade of yellow-green". The really difficult thing about this color (see this website) is that it seems that it's 50% red, 50% green, and 0% blue as far as RGB percentages (which probably explains why you see it as a shade of olive green), but by CMYK percentages, the color is 100% yellow + 37% black, which is probably why I saw it as a muddled gold color. In any case, the color is not a web-safe color, so I think, ideally, the original file should be modified to be a web-safe color; that way, the color would be easily describable. The Obento Musubi (talk) 19:39, 23 July 2020 (UTC)[reply]
As long as the colours are distinct and a matching key is provided the purpose of the diagram is (in my opinion) achieved. Of course there is the issue of device ability to render colours and personal perception of colours when it comes to naming. Personally I would see Brown, Blue and Green - but does it matter in this context.
109.180.186.210 (talk) 10:21, 3 December 2021 (UTC)[reply]
I am puzzled (and intrigued) by your statement: [World Language is] "an article on how the term world language has been used in academic literature". It does of course make it clear that I was quite wrong to write: The key question here is: "Which languages should be listed as having world status, distinguishing them from just the 'supra-regional' ones?"
However, I am not the only editor with the impression that an essential feature of the article - is to present examples of languages with [what could be described as] "World status", followed by others which "do not quite make the grade". You must have noticed that Taryan recently promoted Hindi/Urdu into the second category.
Frankly, I am not personally bothered by the fact that Spanish has been pushed down into the second category. It is true that it is (now) my second language, but for most of my life it was not. You may recall that, not too long ago, I intervened quite forcibly to retain French in second position above Spanish.
Thus, I was only trying to be helpful when I posted: Spanish seems to feature well in two portions of the globe ... so I am reluctant to 'demote' [it]. It is misleading and unfair to say: DLMcN thinks that "Spanish is indisputably dominant in the western hemisphere (and thus is widely taught in the USA, Brazil, and in non-Hispanic islands of the Caribbean), and is important in western Europe, etc. etc." - because < these are facts which are so obvious that it seems superfluous to insist on sources to back them up.
Asking an admin to ban all further discussion of this topic, is surely not the best way of resolving the matter? Rather, it is going to need a complete restructuring and rewrite of the article - to reflect your description of it (quoted at the beginning of this post).
Thank you Lili ... After a short exchange of views with IamNotU - see https://en.wikipedia.org/wiki/User_talk:IamNotU#Another_James_Oredan_sockpuppet?_-_or_not? > no. 87 - [admittedly starting with a completely different topic] - I suggest that we should perhaps not have three separate sections, but simply run the whole list through without any dividing lines. We could maintain the present ordering - but emphasise that the 'ranking' presented, was only approximate - i.e., not meant to be taken too literally. Selected comments after each language [based on sources if necessary] would then give some idea of how widely they were spoken, taught and used. I mentioned your name because I thought you would probably have access to references 1, 2, 29 and 30. Cheers --DLMcN (talk) 20:18, 25 August 2020 (UTC)[reply]
Hi. Another slight problem in e.g. ⟨ᶜ̧ ᵊ˞ ⟩, the modifier letter is composed of finer lines than usual, while the diacritics have normal thickness, which looks odd when they intersect. (It also looks odd with diacritics that don't intersect, but less obviously.) But that's really only a problem if you wanted to use Noto for printing, which it's not really designed for. For the internet it's good enough. — kwami (talk) 10:21, 22 August 2020 (UTC)[reply]
Hi @LiliCharlie: I absolutely agree with what you said when you reverted my edit. Though, what I had meant was that the significantly-different characters are the simplified and Japanese ones, while the compatibility ideographs were "similar variants". Unfortunately, I did not word that clearly and I am not very familiar with Unicode (thanks for linking to the relevant pages!), so it seems that came across wrong. If you know how to properly explain what I was trying to say, that might be helpful, or it could just be left off. I'll switch the character in the traditional column of the chart back to the traditional version since I think that edit is appropriate (do correct me if I'm wrong though) and leave the paragraph as is. Thanks again, ChromeGames923 (talk · contribs) 21:47, 25 October 2020 (UTC)[reply]
Hi ChromeGames923, the characters U+F908 龜 and U+F907 龜 were encoded for what is known as "round-trip compatibility" with existing encoding schemes, so that any text can be converted from other encodings to Unicode and converted back to the original encoding without loss. However in Unicode itself they are considered equivalent to U+9F9C 龜 rather than "similar variants". This means, among other things, that fonts and renderers are not required to distinguish between them. To give you an idea, the following fonts on my system have three identical glyphs for them: AR PL New Kai, BabelStone Han, Batang, BatangChe, Code2000, DFHKStdKai-B5, DFPHKStdSong-B5, DFKai-SB, Dotum, DotumChe, Gulim, GulimChe, Gungsuh, GunsuhChe, HanaMinA, Han-Nom Minh, HYHaeseo, Kurinto fonts in 44 styles, Malgun Gothic, Meiryo, Meiryo UI, MOESungUN, New Batang, New Gulim, TH-Jeong-H, TH-Jeong-J, TH-Ming-HP0, Yu Gothic, and Yu Gothic UI. As you can see, this listing includes fonts from (and for) six major locales: Mainland China, Taiwan, Hong Kong, Japan, South Korea, and Vietnam. (And it seems our Wikimedia software converts U+F908 龜 and U+F907 龜 to U+9F9C 龜, which is no problem for characters that are not the result of conversion from other encodings. Or is it my browser that does the conversion?) — You simply cannot expect the three to be visually different without language mark-up, and the necessity for such mark-up is already discussed in the article, and amply exemplified in the chart of section "Examples of language-dependent glyphs". — The simplified characters U+9F9F 龟 (Mainland China, Singapore, Malaysia) and U+4E80 亀 (Japan) are already in the chart of the "Examples of some non-unified Han ideographs" section. Love —LiliCharlie (talk) 23:06, 25 October 2020 (UTC)[reply]
At Talk:ß#Decisive_arguments, you write “... this CSS-generated ß looks like two S's ... and you won't be able to highlight one of the S's individually”. That is true on my computer, too. (Although it displays it as if it highlighted first the first S, and then the other with its adjacent space). But where is that defined? I searched those listed in Help:Cascading Style Sheets that I thought might apply (i. e. common/shared.css, monobook/main.css, MediaWiki:Common.css, MediaWiki:Monobook.css), but can't see it. Another thing I found odd but might understand if I had access to the CSS is that the ß copies as a simple uppercase “S” via clipboard. ◅ Sebastian23:36, 3 November 2020 (UTC)[reply]
The CSS-3 specification says: "The ‘text-transform’ property only affects the presentation layer; correct casing for semantic purposes is expected to be represented in the source document." Among other things this means it affects only how characters display, not their number or identity. (BTW, my Firefox browser copies ß as lowercase ß to the clipboard, i.e. it also preserves "correct casing for semantic purposes ... in the source document.") The specification stipulates a little lower: "The UA must use the full case mappings for Unicode characters", which means that ß must be transformed to SS. By Wikipedia standards, this is probably WP:SYNTHESIS, but the only interpretation is that the result of the transformation must be a single-character ß. — The CSS property "text-transform" only affecting the presentation layer but not the number of characters is essential for letter spacing: Straße transformed to uppercase with a letter spacing of 0.3em yields Straße; there's an increased spacing between six characters rather than seven. Love —LiliCharlie (talk) 01:46, 4 November 2020 (UTC)[reply]
Thank you for your detailed and interesting reply. All I wanted to know, though, was: Which concrete CSS file drives that behavior in our case? Sorry for your extra work; my parenthetical remarks probably contributed to the misunderstanding by making the question look bigger than it was intended. ◅ Sebastian14:05, 4 November 2020 (UTC)[reply]
If that's what you're asking: The CSS code is the text-transform:uppercase; in the code <span style="text-transform:uppercase;">'''ß'''</span> which is similar to the example given in the lead of article Span and div (where the CSS code is color: red;). The files you are referring to define styles that apply to several or all Wiki pages a user views, but in this case I wanted my code to apply only to a few characters on one Wikipedia page in a way that doesn't require readers to edit their user-defined CSS files. Love —LiliCharlie (talk) 22:48, 4 November 2020 (UTC)[reply]
Oh, thank you! I expected too much of an explicit definition; it didn't occur to me that that specific behavior is already part of the standard behavior for text-transform:uppercase;. ◅ Sebastian16:04, 12 November 2020 (UTC)[reply]
In Italian, ŋ is a separate sound that is under "N" but it is costant and part of our phonetics, so it is a costant sound when it ends with "N" and starts with "G" or "C (K)".
I don't understand, it's not a dialectal difference, nation wise it is pronounced like that.
--Egosivexisto (talk) 20:37, 8 November 2020 (UTC)[reply]
Yes. More precisely, the phone[ŋ] (velar nasal) is the allophone of the phoneme/n/ that occurs before velar consonants. In other words: There is a rule when /n/ is pronounced [ŋ], and you mention that rule in a non-technical way, but since [n] and [ŋ] cannot occur in the same environments (before the same consonants) they never contrast to distinguish words or phrases, and are not separate phonemes. Therefore, a table of phonemes is not the right place for the Italian velar nasal. (Similarly, the phone [ɱ] (labiodental nasal) only occurs before labiodental consonants. The general phonological rule is that Italian sequences of nasal+consonant are homorganic, as in Spanish, but unlike in English and German.) Love —LiliCharlie (talk) 22:04, 8 November 2020 (UTC)[reply]
Hi colleague, it's the first time I open a discussion in a foreign Wikipedia, I'm from the Italian Wikipedia! I took the most conservative versions (Small Seal) from the Shuowen Jiezi and a dictionary of Chu' Nom with Chinese characters variants, https://www.zdic.net/ and https://hvdic.thivien.net/. If you don't like 示, feel free to change it. I spent more or less two weeks doing the reconstruction of all 540 characters (that is to say, I explained their origin and found the correct version. I also did the whole reconstruction of the current version of the HSK4). Sorry if I didn't put the sources, this is not random, I put many efforts in this work :3 Cicognac (talk) 23:53, 15 November 2020 (UTC)[reply]
The best source for Han character correspondences of seal script characters that I know is the electronic Wenlin Dictionary. It contains all Shuowen characters and their original definitions in seal script (in vector format, created by the people who also created the Character Description Language) along with the same content on two levels of Han characters: Older ones that are usually closer approximations of the original seal script, and modern ones.
MPF, I can't find the Shuowen Jiezi dictionary in the website you gave me. Where did you retrieve it from, exactly? I would like to put the original version, the most conservative version in the list since they ARE the Shuowen radicals (I'm not interested in other versions than the Small Seal for this topic). What we use today are either traditional or simplified characters and, while doing philology, they are quite useless: if you can show to the reader a conservative version and/or the original version, that's better. The same applies to the Shuowen radicals. That's why I put all that corrections in the Italian version of the article, https://it.wikipedia.org/wiki/Radicali_dello_Shuowen_Jiezi. It's 100% mine, many of the longest articles in Wiki.it are mine. The longest article in Wiki.it was the reconstruction fo the HSK4, which is now split in 5 parts. As for this handful of correction, if they're not enough and you know a better source with variants, we could use that to add more corrections. As I told you before, I found a lot of variants in the Han Tu Tu Dien and I compared them to the Small Seal version in this dictionary and in the Shuowen Jiezi definition in zdic.net. There shouldn't be many corrections missing, so you can simply copy the existing version and put the corrections. What is your best source, exactly? Can you copy and paste the exact link to the page? (I'll only use free dictionaries in this moment). To conclude, if you think that my version is quite ok, you can copy and paste from my version, it will take you 10 minutes more or less. I've already done the whole research. I'm waiting for your source. Thank you! Cicognac (talk) 09:47, 16 November 2020 (UTC)[reply]
The Wenlin Dictionary is neither online nor free; it is a computer programme, and it is not exactly cheap. — I have decided to produce a PDF in searchable PDF/A-3b archive format that I'll upload to the Commons, but this will take some time because I intend to build a dedicated Shuowen radical font for that, with the seal glyphs in the Private Use Area and the Han characters in a homogeneous style. (I'm not sure if all the outdated Han characters needed are already encoded in Unicode. Though the dictionary uses Unicode where possible, it doesn't depend on it and contains non-Unicode Chinese characters in Character Description Language format.) — The PDF will be expandable, i.e. it will be possible to add Han characters from other sources, and then upload revised versions of the document to the Commons. Love —LiliCharlie (talk) 04:14, 17 November 2020 (UTC)[reply]
What if we wait for the Unicode creation and standardization of the Shuowen Jiezi characters? They started a year ago, it shouldn't take them too much time, after they have finished we can download the font and use it (they're also standardizing the oracle bones characters). Otherwise, I can wait for you personal standardization. I can buy stuff, but I think I'll buy a nice dictionary of 字源, I am not so willing to buy the Wenlin Dictionary. It doesn't bother me, in this moment I'm not dealing with them and I can wait, in the meanwhile I can work with many other possibile topics (i.e. the Sino-xenic pronunciation), other projects and have a break (I worked non-stop work 2 months). No, I think some characters are not encoded. I did my best with the available variants, for now I think it's ok. If you don't like my version of the radicals, it doesn't matter. Now that I know that Unicode is creating a font for these characters, I/we can have a look from time to time. This is a good news for those who work with these characters. If need be, feel free to start a conversation in my talkpage in the Italian versions, foreigners are always welcome! Cicognac (talk) 22:59, 17 November 2020 (UTC)[reply]
Unicode did not start to discuss the encoding of seal script characters a year ago. This goes back to 2003, see their page Topical Document List: Seal Script. (I recommend viewing the proposal and charts of 2019-06-19, as well as the later documents. Richard Cook who repeatedly contributed to that discussion is one of the authors of the Wenlin Dictionary, as well as one of the two creators of the Character Description Language.) Also note that seal script hasn't made it to the Uncode pipeline yet, and that the Unicode Consortium does not provide fonts for public use — Unicode doesn't encode glyphs, but characters —, and that wide-spread font support (esp. in OS distributions) may take a decade or so to take effect.
I am preparing the PDF because I don't expect you to have access to the Wenlin dictionary. It will inform you of its content, and enable you to add more Han characters that correspond to seal script Shuowen radicals. Love —LiliCharlie (talk) 20:25, 19 November 2020 (UTC)[reply]
Hello! Voting in the 2020 Arbitration Committee elections is now open until 23:59 (UTC) on Monday, 7 December 2020. All eligible users are allowed to vote. Users with alternate accounts may only vote once.
The Arbitration Committee is the panel of editors responsible for conducting the Wikipedia arbitration process. It has the authority to impose binding solutions to disputes between editors, primarily for serious conduct disputes the community has been unable to resolve. This includes the authority to impose site bans, topic bans, editing restrictions, and other measures needed to maintain our editing environment. The arbitration policy describes the Committee's roles and responsibilities in greater detail.
Ehi, LiliCharlie, did something happened in the last 2 weeks more or less? You didn't finish the last part of the revision of the Radicals chart, there is a handful of addenda missing, then the chart can be posted for everyone's use! In this moment, my internet connection is working (I have had problems in the last few days), so I can try to contact you. Cicognac (talk) 09:35, 15 December 2020 (UTC)[reply]
Hello LiliCharlie, may you be surrounded by peace, success and happiness on this seasonal occasion. Spread the WikiLove by wishing another user a Merry Christmas and a Happy New Year, whether it be someone you have had disagreements with in the past, a good friend, or just some random person. Sending you heartfelt and warm greetings for Christmas and New Year 2021. Happy editing, JACKINTHEBOX • TALK16:18, 24 December 2020 (UTC)[reply]
"All basic letters outline their articulator's shape and phonetic features when pronouncing them" is conciser than current version with the same meaning.
I don't think your first comment hits the big picture of my changes.
"it takes TWO articulators to produce an articulatory stricture (usu. an active and a passive one, or two active ones in the case of glottals and, to some degree at least, bilabials as well"
I can buy the second comment. — Preceding unsigned comment added by Luminans (talk • contribs) 04:13, 27 December 2020 (UTC)[reply]
OMG, I reverted to the wrong version using Twinkle (not manually). It seems I didn't realise you had just made the edit I intended to make, and I confused the left side of my screen (showing the spam link) with the right one (link removed). Thanks for correcting my mistake. Love —LiliCharlie (talk) 23:59, 28 January 2021 (UTC)[reply]
I have seen you reverted the change to oromo language. according Ethnologue, oromo has 34mil speakers which is updated on the oromo language page. south, west, central,east oromo speakers are under one Oromia state of Ethiopia. oromo has One language in spite of little dialect within the some of 21 administrative zones of oromia, they all mutually intelligible. The 2011 census reported the population of Oromia as 35,000,000; this makes it the largest regional state in population. Oromia is also the largest regional state and the world's forty-second most populoussubnational entity, and the most populous subnational entity in all of Africa.
In the following source oromo speakers is 34 million Oromo at Ethnologue (18th ed., 2015)
Borana–Arsi–Guji–Wallaggaa-Shawaa Oromo at Ethnologue (18th ed., 2015)
Eastern Oromo at Ethnologue (18th ed., 2015)
Orma at Ethnologue (18th ed., 2015)
West Central Oromo at Ethnologue (18th ed., 2015)
Waata at Ethnologue (18th ed., 2015) MfactDr (talk) 09:08, 16 February 2021 (UTC)[reply]
little bit background of the language. With 33.8% Oromo speakers, followed by 29.3% Amharic speakers, Oromo is the most widely spoken language in Ethiopia.[1] It is also the most widely spoken Cushitic language and the fourth-most widely spoken language of Africa, after Arabic, Hausa and Swahili.[2] Forms of Oromo are spoken as a first language by more than 35 million Oromo people in Ethiopia and by an additional half-million in parts of northern and eastern Kenya.[3] It is also spoken by smaller numbers of emigrants in other African countries such as South Africa, Libya, Egypt and Sudan.
Hello there, I think u’ve made a mistake about total number of speakers. The page has ignored people with Persian language as their second language and it’s kinda disrespectful to ignore those people. Total number of Persian speaking ppl is around 110 million and u can find the references under my edition of the page. So please go read the references before rewinding the page to the 55 million version. With considering Persian speakers population only as 55 million, you are ignoring Iranian kurds, Iranian Turkmens, Iranian Arabs, Iranian Baluchs, Iranian Azeris, Iranian Armenians, Iranian Georgians, Iranian Lurs, Iranian Bakhtiaris etc. all of these ethnicities speak Persian as their second language which is not considered by Wikipedia which may bring rage and hate against wikipedia. There are also other people in Afghanistan, Tajikistan, Pakistan, Uzbekistan, Iraq, Bahrain etc. who speak Persian as their second language. We don’t care if the unified source is complete or not. We just care about being considered in the numbers. So please respect us and consider us as people with their second language as Persian.
Thank you. My big weakness is closing brackets and such. Also, I know that I haven't been consistent with s versus 's' or even "s". And maybe I should actually have used ⟨s⟩ (but ⟨long s⟩ is not correct, so perhaps not). "Your mission, if you choose to accept it... etc etc.--John Maynard Friedman (talk) 00:15, 25 February 2021 (UTC)[reply]
At the risk of rehashing an old argument... where was the consensus formed to use {{char}}? The TfD was closed as kept but that was precisely so that the use of the template, not the template per se, could be hashed out elsewhere. Did that happen? Nardog (talk) 08:32, 25 February 2021 (UTC)[reply]
As far as I know, I limited my use of {{char}} to the just those cases where the character being discussed needs to be isolated for that purpose.
In this case, we have an unusual and unfamiliar symbol that certainly needs to be mounted on a microscope slide, as it were. (I see no similar reservations about {{code}}, which is in widespread use despite its rendering the symbol(s) in monospace and so distorting them.) I have used {{angbr}} for graphemes and (more controversially) digraphs. If there are any cases where angbr is more appropriate, I have no objection to that change. I am far more concerned about unhelpful markup like parentheses, quote marks and (far worse) italics. --John Maynard Friedman (talk) 09:49, 25 February 2021 (UTC)[reply]
Rereading the article this morning as a final copy-edit, afaics {{char}} appears exactly twice, once with a long s and once with a round s. Short of outright opposition to the template being used in any context, I don't really understand your point? All it does is draw a one-pixel square around the symbol under examination. It doesn't intrude. It is invisible to screen readers without affecting their function. It doesn't affect people with visual impairment using magnifiers like italics do. Short of outright opposition to the template being used in any context, I don't really understand your point?--John Maynard Friedman (talk) 13:55, 25 February 2021 (UTC)[reply]
Hello! Voting in the 2021 Arbitration Committee elections is now open until 23:59 (UTC) on Monday, 6 December 2021. All eligible users are allowed to vote. Users with alternate accounts may only vote once.
The Arbitration Committee is the panel of editors responsible for conducting the Wikipedia arbitration process. It has the authority to impose binding solutions to disputes between editors, primarily for serious conduct disputes the community has been unable to resolve. This includes the authority to impose site bans, topic bans, editing restrictions, and other measures needed to maintain our editing environment. The arbitration policy describes the Committee's roles and responsibilities in greater detail.
I read the article which deals with this accent, and, accordingly, I didn't understand whether this accent was chiefly British or American. Listening to Katherine Hepburn convinced me that this accent was predominantly British, to say nothing of Billie Burke. I'm a novice in phonetics, so could you help me with answering this question? Роман Сергеевич Сидоров (talk) 07:54, 23 October 2022 (UTC)[reply]
Hello! Voting in the 2022 Arbitration Committee elections is now open until 23:59 (UTC) on Monday, 12 December 2022. All eligible users are allowed to vote. Users with alternate accounts may only vote once.
The Arbitration Committee is the panel of editors responsible for conducting the Wikipedia arbitration process. It has the authority to impose binding solutions to disputes between editors, primarily for serious conduct disputes the community has been unable to resolve. This includes the authority to impose site bans, topic bans, editing restrictions, and other measures needed to maintain our editing environment. The arbitration policy describes the Committee's roles and responsibilities in greater detail.





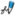 or
or  ) located above the edit window.
) located above the edit window.

 Done. I have deleted that edit. Love —LiliCharlie (talk) 13:38, 23 February 2017 (UTC)
Done. I have deleted that edit. Love —LiliCharlie (talk) 13:38, 23 February 2017 (UTC)



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[6]](https://commons.wikimedia.org/wiki/File:New_Zealand_English_monophthong_chart.svg){kind=link}

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}