
Wikipedia:Reference desk/Archives/Computing/2010 April 7
| Computing desk | ||
|---|---|---|
| < April 6 | << Mar | April | May >> | April 8 > |
| Welcome to the Wikipedia Computing Reference Desk Archives |
|---|
| The page you are currently viewing is an archive page. While you can leave answers for any questions shown below, please ask new questions on one of the current reference desk pages. |
April 7
[edit]HandyRecovery Help
[edit]I just downloaded the trial version of handy recovery and I was hoping someone here could help explain how I could retreive pictures emptied from the recycle bin, how do I recover those with Handy Recovery? —Preceding unsigned comment added by 71.147.7.50 (talk) 00:56, 7 April 2010 (UTC)
- This program has saved me a few times - one can't always back everything up in time! Choose your C: drive then click Analyze. Then click on the Recycle Bin in the tree list - if there's anything it's able to recover, the files will appear in a list on the right. Choose what you want to recover then click Recover. Recovered files will default to C:\Recovered Files. Good luck and make sure you do this before doing anything else on your computer. The longer you delay, the more the chances are of your files being overwritten. Sandman30s (talk) 21:15, 7 April 2010 (UTC)
Wrongful Article Content Change.
[edit]In the following Wiki - http://en.wikipedia.org/wiki/Nintendo
This change was made
Conrad Abbott: President of NOC
Yuji Bando: Managing Director of Nintendo Australia
Source: http://en.wikipedia.org/w/index.php?title=Nintendo&diff=prev&oldid=354265541
Being a Journalist with Nintendo for 19 years and hundreds of international pages of information being written for Nintendo. I can say that these two Owners of the Nintendo Franchise, Yuji San being recently retired as well as Mr. Abbott being the newest Owner. These two wonderful people who I have interviewed in the past are truly a name to be mentioned and recorded in history.
I have vast amount of information I can contribute to these outstanding people and if I may, I shall write there Wiki if not done so already by the Wikipedia Community.
Known that these edits are being made because of lack of knowledge and references, it is still disappointing to see these fine people and others being removed from there place in Wiki history.
Thank You Gratefully, Kuju Yoshiamo (Senior Editor, Asia Media)Kuju Yoshiamo (talk) 04:16, 7 April 2010 (UTC)
- Answered on this user's talk page. Comet Tuttle (talk) 04:41, 7 April 2010 (UTC)
Placing captions beside figures in LaTeX (beamer)
[edit]I'm trying to achieve something like the picture of the giraffe with side caption under the heading "Side Captions" here:
http://en.wikibooks.org/wiki/LaTeX/Floats,_Figures_and_Captions
however the line in their code
\usepackage[pdftex]{graphicx}
results in the error message "Option clash for package graphicx..."
If I try to compile without the usepackage command, the LaTeX compiler seems to hang forever.
I am using documentclass "beamer". Without that I don't get the option clash error message, but this is for presentation, so I don't want to abandon beamer for this reason.
I have searched the internet and found some hacks to accomplish something similar involving minipages, but they don't adjust well to my particular situation.
Anyone figured out how to place captions beside figures in beamer documents? —Preceding unsigned comment added by Heatkernel (talk • contribs) 05:48, 7 April 2010 (UTC)
- Beamer gives you a lot of manual control. I don't think you should rely on a figure environment and hacked side-captions, but rather determine which boxes should go where manually. Yes, this sucks, but then so do slides in general ;-). --Stephan Schulz (talk) 14:28, 7 April 2010 (UTC)
- Stephan Schulz: if I knew how to "determine which boxes go where manually" I wouldn't be asking this question. Would you care to post a link explaining how to do that or explain what you mean? Thanks! Heatkernel (talk) 16:35, 7 April 2010 (UTC)
- Sorry, I've only ever made 2/3rds of a lecture series with Beamer so far, and was so pressed for time that I was glad to get the contents right, never mind the formatting. But a simple (if inelegant) fix is to use a tabular environment with the image in one and the caption in the other column, or to use minipages. Take a look at http://www.eprover.org/TEACHING/TGSE2009/TFSE06.pdf, page 07. Ignore the German language ;-). The source for that (image and text next to each other) is as follows:
\includegraphics[height=0.9\textheight]{IMAGES/300px-Burj_Dubai_20090916.jpg}
\hfill{}
\begin{minipage}[b]{0.6\textwidth}
\begin{itemize}
\item Höhe 818m
\item 162 Stockwerke
\item 57 Aufzüge
\item Aufzughöhe bis 504m
\item Geschwindigkeit bis 10m/s (36 km/h)
\item Doppelstöckige Aufzüge
\end{itemize}
\end{minipage}
- Does that help? --Stephan Schulz (talk) 17:07, 7 April 2010 (UTC)
- That helps a lot. Thanks! Heatkernel (talk) 03:25, 8 April 2010 (UTC)
Internet
[edit]Where is the Internet's control centre? jc iindyysgvxc (my contributions) 13:24, 7 April 2010 (UTC)
- There isn't one. The whole point of the internet was initially to be a decentralized network that could survive having major sections removed. That being said, it is not a totally decentralized network (or, more specifically, it is decentralized but not distributed), owing to the way that undersea cables work (they cluster at points), so some countries have relatively centralized connections (that is, most of their connections eventually lead through a few distinct points). But there is no control center—no control, and no center! A better way to think about it is a network in which you, the user, connect to large hubs, which can then connect to other large hubs, which can then connect to other individual sites. There are lots of hubs. Using a traceroute command you can actually see the connections being made. From my computer (near Boston) to Wikipedia, I first go through a manner of local (Massachusetts) hubs, then end up being routed through New York, then through Washington, then Atlanta, then Dallas, then to Florida, then finally to the computers that Wikipedia lives on (19 hops total, in this particular example). The network is set up so that if one of these hubs went down, the connection would find a way around it... all in a blink of an eye! --Mr.98 (talk) 13:28, 7 April 2010 (UTC)
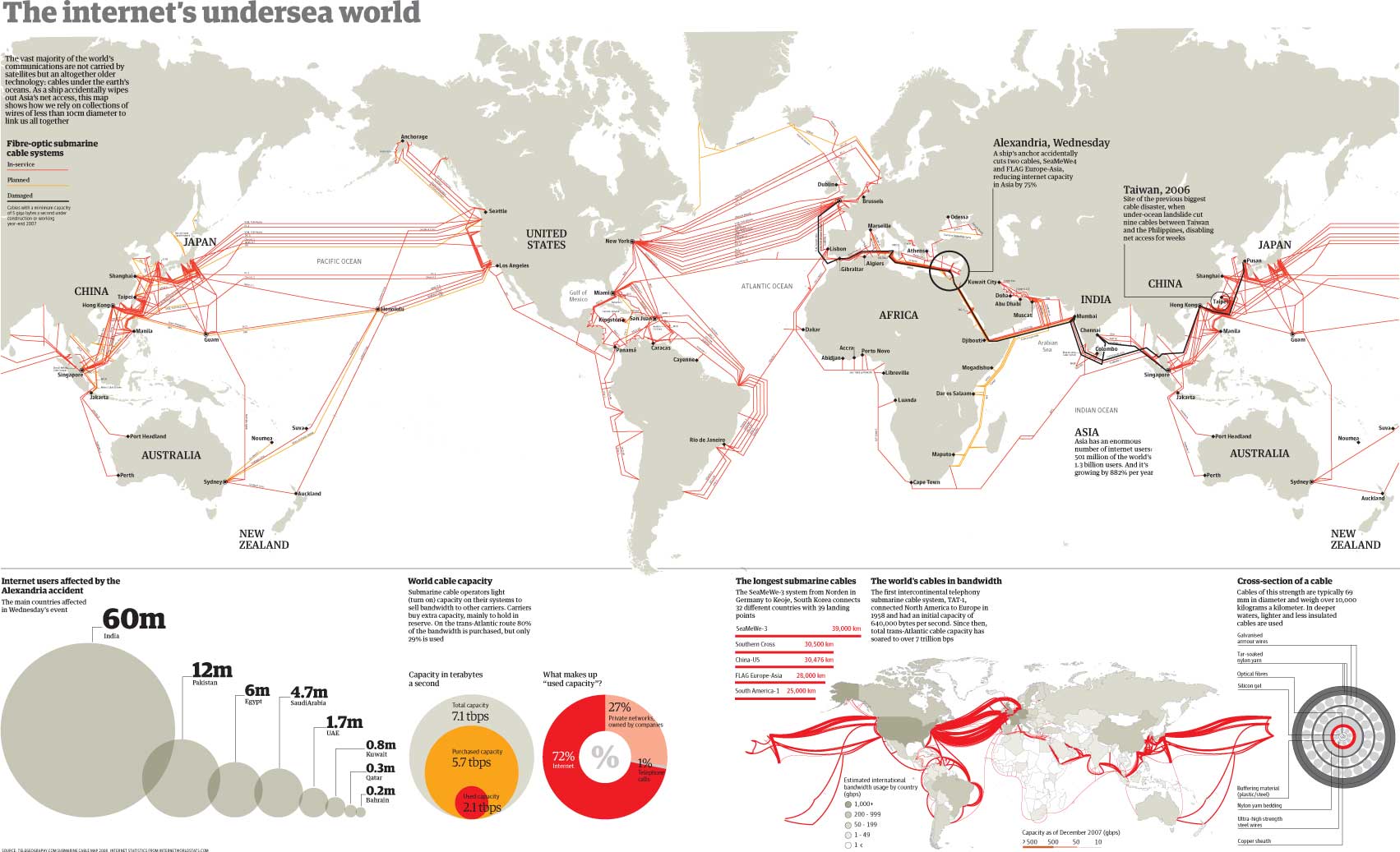{kind=link}
- Think of it like airports. There isn't one central airport which all planes fly through, right ? And, if an airport unrelated to your flight is shut down, it shouldn't affect your flight (except that some traffic through that airport may be rerouted through yours, slowing things down a bit). And, even if an airport on your flight route shuts down, they may be able to reroute your flight through another. So, no one airport is critical, but if enough shut down, as after 911 in the US, then that does stop traffic. StuRat (talk) 13:42, 7 April 2010 (UTC)
- That said, there is ICANN, a centralized authority in charge of, essentially, assigning domain names. Without some centralized authority, it'd be essentially impossible for everyone's computers to agree on what, say,
wikipedia.orgmeans. All the infrastructure (except the root nameservers that ICANN controls) is decentralized. In fact, even the root nameservers are numerous, and spread all over the globe. Paul (Stansifer) 14:20, 7 April 2010 (UTC)
- Click the links to enjoy this story. Once upon a time there were many LANs. Some were just a few computers connected together and some grew to lots of computers using one or more Network switches to move data efficiently. Then came the idea of connecting the LAN's together into a WAN which is made possible by Routers. Before you could say Internet everyone could connect to everyone. For that to work every computer has to be given an IP address, just like every telephone is given a number. That's where the similarity ends because while you might be able to remember the telephone number of, say, the Wikipedia office (?), people like the way the system recognizes an easy to remember name like www.wikipedia.org so you never need think of the numerical IP address. It was once rumoured that the whole Internet is controlled from the bedroom of a 13-year old named Jason. Cuddlyable3 (talk) 19:51, 7 April 2010 (UTC)
- Well, that would explain all the porn, wouldn't it ? :-) StuRat (talk) 00:57, 8 April 2010 (UTC)
- These answers all have too much love for ICANN, not enough for ARIN and the other RIRs. Without DNS you'd have to memorize a lot more numbers, but what would you do without the numbers? 98.226.122.10 (talk) 07:56, 8 April 2010 (UTC)
- We'd use bang paths! -- Coneslayer (talk) 16:19, 8 April 2010 (UTC)
- Bang paths are not guaranteed to yield a globally-qualified destination - so if some member of the network fakes his machine name, not only is this impossible to detect, but there's nobody to complain to in order to get it fixed. That's why we have IANA. Nimur (talk) 17:24, 8 April 2010 (UTC)
- We'd use bang paths! -- Coneslayer (talk) 16:19, 8 April 2010 (UTC)
- I don't see IANA either. IANA does a very important thing: it makes sure that you can't lie about your IP. This is even more fundamental than DNS - it prevents two AS networks from using the same IP subnets, ensuring a globally unique destination. The route paths are distributed and decentralized, but the route destinations are controlled by an authoritarian system. If you disobey and try to connect an AS which uses an unassigned number (an invalid route table that does not comply with the IP numbers you are permitted/assigned to have), Border Gateway Protocol will deny you access to your peers, and your entire AS will be shut down from internet connectivity. Nimur (talk) 17:15, 8 April 2010 (UTC)
KDE on Windows--Plasma Desktop won't launch apps
[edit]When I use Plasma Desktop and the Application Menu widget, the applications won't launch. They launch if I use the Start Menu shortcuts, though. I have Windows 7; could this be a permissions problem or is it just a glitch? Buffered Input Output 14:24, 7 April 2010 (UTC)
Copying from a pdf file
[edit]I'm sure there's a way to do this, but I don't know how. I have to copy large chunks of text from a .pdf file and I don't want to copy it by hand if I don't have to. How can I do a cut and paste to a Word document? I've tried highlighting, but the copy function isn't available. Thanks. InspectorSands (talk) 15:24, 7 April 2010 (UTC)
- If the copy function is unavailable, it's probably because the PDF has that feature specifically disabled. iText may be able to get it anyway. -- Finlay McWalter • Talk 15:41, 7 April 2010 (UTC)
- I'll give it a try. Thanks for the help.InspectorSands (talk) 16:10, 7 April 2010 (UTC)
- Is the PDF of a scanned page image? If you zoom in on the text, does it render cleanly or does it become chunky/blurry pixels? If it is the latter, it might not have had OCR run on it, and might not be copyable in that way. (Even with OCR on it, the copied text will probably have some errors, but that's a different problem.) If it is the former, it might be permissions, yeah. --Mr.98 (talk) 16:17, 7 April 2010 (UTC)
- If there is a lock icon in the lower-left corner of the screen in Adobe Reader (or Acrobat), then the creator of the PDF has restricted what you can do with the file. If you double-click on the lock, it should tell you what the restrictions are. You can use a PDF password removal program to clear the restriction. The following program works well for doing that. I use it all the time: [1].--Chmod 777 (talk) 19:18, 7 April 2010 (UTC)
- You can always copy your PC screen display as a picture. Press Alt-PrtSc. Then open Paint. Then ctrl-V (means "Paste"). It's only a picture and not editable text but you can Save it in a file or insert the picture in a Word document. Cuddlyable3 (talk) 19:19, 7 April 2010 (UTC)
- also, not every pdf has a text image imbedded; some scanned items are stored in the pdf as images only, so that there is no way at all to extract the text from the pdf since the text doesn't actually exist. you realize, naturally, that it requires an additional step of OCR to produce the text after the image is scanned, so it's relatively easy to NOT produce it. of course, any pdf found by google search must have a text imbedded in it. i don't know if such pdfs can be set up to no allow text extraction, or conversely if locked pdfs are indexable by google. anybody know? Gzuckier (talk) 06:11, 8 April 2010 (UTC)
- Content copying can be disabled on all PDF since whatever version added that DRM feature. Of course not all readers may enforce it (although even some FLOSS ones do, at least by default). Note that it doesn't just prevent copying of text but images too (although can't stop a screen capture).
- If enabled, while not definitive, a quick search suggest the view as HTML option may disappear but the file may still be indexed, which makes sense. In fact I seem to remember something like this before, where there was a 'bug' either with this feature or the similar Gmail one or something where the option was available even if content copying is disabled.
- Interesting enough, it seems if you're using a text based browser Google offers a text based version by default. I wonder what happens in this case if content copying is disabled but content copying for accessibility is not?
- Note that some PDFs, particularly of old documents and also Google Books stuff has a scanned page which is in the foreground but OCRed (but perhaps not well/ proofread) text in the background so it can be indexed and searched.
- Nil Einne (talk) 17:53, 13 April 2010 (UTC)
Why must ads cause so much misery?
[edit]Most of what I do on the Internet, other than a few select sites, I do at libraries.
I doubt they would block ads, though some have, briefly.
Yesterday the computer just froze and at the bottom of the screen it said the computer was waiting for some site that I know was ad-related. It certainly wasn't the newspaper article I was trying to look at.
If I have the article I want, why can't it just give up if it can't find the ad? Or if I don't have the article but the thing gets hung up on an ad that's not essential?Vchimpanzee · talk · contributions · 18:57, 7 April 2010 (UTC)
- Install Adblockplus 82.44.54.207 (talk) 19:08, 7 April 2010 (UTC)
- (ec)Some browsers can be configured to do incremental rendering as well, so the page can (mostly) load without the ad. It leads to some screwed up formatting at times (particularly if some of the layout is controlled by CSS or JavaScript served from another slower server), but it would partially solve your problem in many cases (excluding those cases where the page layout is completely dependent on the ad). That said, I haven't needed a feature like that in years, since I'm running Firefox with Adblock Plus and NoScript, which, as the IP above notes, circumvents the problem. As such, I have no memory of how to enable incremental rendering on the browsers which (may) still support it. —ShadowRanger (talk|stalk) 19:19, 7 April 2010 (UTC)
- Also, disabling Java Script (Tools + Options in Firefox) stops the worst ads, with crap flying across the screen. You may need to occasionally enable it for something to work, but then disable it again to kill the annoying ads. StuRat (talk) 19:16, 7 April 2010 (UTC)
- In my experience, at least four websites out of ten require JavaScript to render intelligibly nowadays. Another four in ten don't need it, but look funny without it. If you're going to go to the trouble of managing JavaScript execution, you may as well use NoScript (so you can control which domains are allowed to execute) rather than using the all-or-nothing hammer of global JavaScript disabling. —ShadowRanger (talk|stalk) 19:22, 7 April 2010 (UTC)
- Expanding Vchimpanzee's question: When a browser loads an HTML page that has, say, 20 images on the page, doesn't the typical browser parse the page and send out 20 fetch requests for the images in a big batch, and then update the page as the images come in? It sounds to me like Vchimpanzee is having a problem where a commercial site waits until the images load before it displays the content that Vchimpanzee is interested in, which I remember having problems with back in the dial-up days. (Like ShadowRanger, I haven't had problems like this in years, because I use Firefox with Adblock Plus.) Comet Tuttle (talk) 20:10, 7 April 2010 (UTC)
- The sites normally load the way they're supposed to. I don't know what was happening yesterday or even what version of Internet Explorer was being used. But it's a library, and they're unlikely to block ads.
- A related problem would happen with Firefox at another library, but it hasn't happened lately. It would just freeze completely for certain ads.Vchimpanzee · talk · contributions · 20:17, 7 April 2010 (UTC)
- There's another question I asked which got answered when messages started showing up saying Javascript was disabled and I couldn't do certain things. THIS the library can fix, and I'm going there tomorrow hoping they have.Vchimpanzee · talk · contributions · 20:21, 7 April 2010 (UTC)
- @Comet Tuttle: "doesn't the typical browser parse the page and send out 20 fetch requests for the images in a big batch" - the answer is "it depends". Originally, in http1.0, this wasn't true: if you had 20 images, the browser would open 20 fully independent sockets to the server, issue a single GET request on each, read the resulting image, and close that socket. That was obviously very inefficient, and (because browsers initially only used a few sockets) very slow. http1.1 added HTTP persistent connections which allows clients to keep alive a socket, so each request didn't necessitate establishing a fresh tcp connection. But that still means 20 http request-response pairs. So, with modern browsers, one would ideally use CSS sprites, where many images are encoded into a larger image, and one uses CSS to display only the parts you want. That way there's only one get/response cycle to service many images, but this relies on the browser supporting the relevant CSS properly - and (as usual) IE6 (which is still around too much to ignore) needs special treatment and also lacks proper PNG transparency support, which makes CSS sprites more flexible. Add to that the bother of organising graphics serverside into such groups, you mostly find that CSS sprites are used for logical groups (like the little graphics which comprise a skin) but not all the graphics on a page. -- Finlay McWalter • Talk 21:16, 7 April 2010 (UTC)
- if a page has a link to a printable copy, that page will be free of most of the ads, since they're not printable. if you get in the habit of hitting the "print" link as soon as it comes up on the page, you can find a more enjoyable browsing experience. occasionally a print page may feature a javascript that causes the print option box to popup automatically, as if you hit the file/print menu item, but it's no sweat to hit the cancel button on that. sometimes the "print" link doesn't take you to a differently formatted page but just pops up the print option box on the current page. fie on that. Gzuckier (talk) 06:15, 8 April 2010 (UTC)
- That printable version idea works. I just tried it on the site that froze Tuesday. I have to remember that in the future.Vchimpanzee · talk · contributions · 18:25, 8 April 2010 (UTC)
- I haven't been seeing any ads. I'm on that computer where Javascript is disabled, and for that reason I am now blocked from one of the sites I want to go to. This is insane. I've told these people until I'm blue in the face to get this Javascript problem fixed.Vchimpanzee · talk · contributions · 18:40, 8 April 2010 (UTC)
- And what are we supposed to do about it? 174.114.4.18 (talk) 19:39, 8 April 2010 (UTC)
- No need to be sarcastic. He wasn't blaming anyone here. —ShadowRanger (talk|stalk) 19:51, 8 April 2010 (UTC)
- Right. That's another question on the desk. I think it's been answered, and the IT people should fix the computers. Why they haven't I don't understand. You'd think people would be rioting over all these difficulties the lack of Javascript would cause.Vchimpanzee · talk · contributions · 20:26, 8 April 2010 (UTC)
- Oh, the reason I mentioned the Javascript problem was that maybe that's a possible solution, since I never saw ads. But it's not really worth it if you're not in control. There is a sign on at least some of the computers at that library, if not all, saying to use Firefox to solve one particular problem. It did seem to work on one of those sites that was blocking me without Javascript. I can use Firefox if Javascript is messing me up, but also Explorer where it works. Apparently.Vchimpanzee · talk · contributions · 18:05, 9 April 2010 (UTC)
- No need to be sarcastic. He wasn't blaming anyone here. —ShadowRanger (talk|stalk) 19:51, 8 April 2010 (UTC)
- And what are we supposed to do about it? 174.114.4.18 (talk) 19:39, 8 April 2010 (UTC)
- I haven't been seeing any ads. I'm on that computer where Javascript is disabled, and for that reason I am now blocked from one of the sites I want to go to. This is insane. I've told these people until I'm blue in the face to get this Javascript problem fixed.Vchimpanzee · talk · contributions · 18:40, 8 April 2010 (UTC)
- That printable version idea works. I just tried it on the site that froze Tuesday. I have to remember that in the future.Vchimpanzee · talk · contributions · 18:25, 8 April 2010 (UTC)