
Wikipedia:Google Books and Wikipedia
This is an essay. It contains the advice or opinions of one or more Wikipedia contributors. This page is not an encyclopedia article, nor is it one of Wikipedia's policies or guidelines, as it has not been thoroughly vetted by the community. Some essays represent widespread norms; others only represent minority viewpoints. |
The document helps explain why we prefer not to use Google Books (GB) where better options exist.
Why Google Books isn't good
[edit]- GB is a commercial book seller. Its parent company is in the business of making money. The following problems all arise from this core truth.
- GB links are unstable and prone to disappear. An estimated 15% of GB links on Wikipedia are dead (404). An even larger percentage of the page previews no longer work and redirect to the "About this book" page. Google is not a library nor archive for long term preservation. Books can and do disappear at any time.
- Publishers can withdraw permissions to view book previews at any time. For example, book previews of most publications by Cengage disappeared in 2023, meaning that links to pages in those books now redirect to "About this book" pages. Wolters Kluwer formerly provided page previews visually identical to the hard copy versions of their works, but in 2023 withdrew those previews and provided alternative page previews generated from e-book versions. Wolters Kluwer does provide in-line notations in its e-book versions to indicate hard copy pagination, but the e-book versions are not visually identical to the hard copy versions (that is, not set in the exact same typefaces) and accompanying illustrations are often either omitted or distorted.
- Book previews are not equally accessible to all internet users. People living in other countries may not be able to view a page in "preview" that you were able to when you used it as a citation.
- Book previews of copyrighted works are restricted to a certain number of pages. It is easy to exhaust that number from a given IP address and device while scrolling through or searching the contents of the book, and then GB will not display any additional pages to that particular IP address and/or device for a very long period of time (several months). Some books have working links and bookmarks allowing for jumps to later chapters, but some do not. It is usually possible to jump to a specific page to begin exhaustion of preview pages from that location by editing the URL (e.g., "&pg=PA100" jumps to page 100), but GB does not educate users about this or provide a user interface to facilitate direct page jumps.
- Searches across GB's entire book database are buggy. When publishers submit multiple editions of a book, GB will often link first to the e-book edition which almost always lacks original pagination. Users must then explore the various editions linked from the e-book edition page, to determine if a hardcover or paperback version was also made available with original pagination suitable for direct citation and direct links.
- Searches within particular books are buggy. For some books, GB provides links from snippets displayed in search results to the corresponding pages. For other books, snippets are displayed as search results but no links are made available, even when the book's pages can be otherwise previewed on GB. This forces users to manually edit URLs as explained above in order to preview those pages.
- Due to digital restrictions management, geoblocking and other barriers,[1] archiving Google Books is hard and sometimes impossible: Wayback Machine and other web archives often fail to archive even the Google page previews specifically linked from articles.
- This is also a problem for accessibility.[2] Libraries like the Internet Archive have specific services for the visually impaired.
- In general, Google Books is not free software and requires the user to run proprietary JavaScript. All its users are monitored for various purposes and privacy concerns regarding Google apply.
- The ostensible reason for user monitoring is to allow Google to respect the contracts it has with publishers, which require Google to make life miserable for readers; however, some such requirements are Google's own creation, see next point.
- Google Books makes governments and public entities sign contracts which go against the public domain by stating that Google has an exclusive right on the scans for a number of years.[3]
- This goes against Bridgeman Art Library v. Corel Corp. and long-standing Wikimedia policy statements and goals: see WMF policy on commons:COM:PD-Art and Wikimedia chapters' statement of intent.
- Google Books tries to make users register a Google account and access books only while logged in, both to make user monitoring easier and to direct users to its paid Google Play offering. It's impossible to know whether in the future an URL which currently works for everyone will become subject to registration or payment: for instance, certain buttons to download a (public domain) book in PDF or EPUB format have changed their positions and requirements multiple times.
- GB shifts content while you are not looking. For example, a link to a 1985 edition might in the future become the 2019 edition because the publisher released a new edition. This is good for book sellers and publishers, because the newest edition of the book is always at the same Google Book ID. For Wikipedia, this causes havoc with page references and citations.
- GB books have free preview for some books but as a commercial book seller they have no interest in freely lending books with CDL (Controlled Digital Lending) like other providers do.
- GB in 2020 started offering "new" GB which ignores significant portions of existing URLs resulting in different final results.
- When searching for a term inside a book from a commercial publisher, it only displays results for those pages that are available for preview. It is not a comprehensive book search.
- GB search is far less comprehensive than it may initially appear. Many commercial publishers with their own online databases behind paywalls will not allow GB to index and search the contents of their books. GB usually knows of the existence of those books, in that book titles appear with a "no preview" annotation when specifically searched for. But their contents never appear in GB search results, even when searching for specific text already known to be present in those books. This requires researchers exploring a particular topic to ascertain whether the leading publishers specializing in that topic have already locked up their content away from GB in commercial databases, and then conduct separate searches of those databases.
- Google Books ingests low-quality AI-generated books, some of which are trained on Wikipedia itself. See "Google Books Indexes AI Trash" (April 4, 2024)
Why we use it anyway
[edit]A 48-hour EventStream poll showed about 400 new Google Books links being added per day to the English Wikipedia (Feb 2020).
- The core strength of Google is search and this is true with Books. It is easy to find a citation for a given search term.
- When it works, GB is marvelously convenient. Traditionally, it takes at least 15 to 30 minutes for an experienced able-bodied researcher who lives next to a research library to visit the library, find and retrieve a cited hard copy book in the library's collection, and verify whether a citation to that book is accurate (i.e., that the book actually states the specific assertion at issue at the cited page). The time burden is much higher for those persons who do not live next to a library, or are physically disabled and have difficulty navigating library stacks. Now one can link directly to the relevant page on GB, and if the link is still working, anyone else can verify the citation in a few seconds.
- GB has greatly expanded access to page images of public domain books. Early e-book projects focused on optical character recognition or manual keyboarding of text, but did not capture full page images. When it works, GB is a wonderful resource for historical researchers who need to see full illustrations and original page layouts.
- When publishers allow GB to index and search their books but not display pages in full, the snippets returned by GB in search results can still be useful. Those snippets can reveal obscure sources which would have been much harder to find through traditional research methods—usually because the particular assertion at issue is a digression from the main topic which would not have been captured in titles, tables of contents, subject classifications, or synopses.
- GB is one way to access many scholarly books. Books from university presses on obscure academic subjects are less likely to be carried by retail bookstores or public libraries. The vast majority of academic books remain inaccessible to anyone who do not live near a major research university with a library that allows public access. Only the wealthiest scholars are location independent in that they can afford the extravagant convenience of buying copies of all potentially relevant books and articles, sight unseen, either as hard copy books shipped to their location or digital works downloaded through paywalls, and then sorting out later which works are actually relevant to a specific research topic. Most researchers still need to visit libraries to download digital works under institutional licenses, or they have to first read through hard copy books in libraries to determine whether they are relevant and then make scans of only the pages they actually need.
- GB is one way to access small commercial publishers based in other countries which are unlikely to see their publications exported or purchased by libraries or bookstores outside of those publishers' home countries. Only the largest publishers are able to regularly promote books to an international audience and arrange for distribution and localization. Only the largest academic research libraries try to regularly import and carry books from small publishers all over the world.
- Market power: especially when searching rare keywords, Google Search links Google Books very prominently. More than 90% of users use Google Search.
- Force of habit and the network effect—the more Google Books links we have, the more we will have.
- Problems are hidden. Most users are unaware of these issues.
- In-line search-term highlighting is very nice.
- For public domain books, Google Books sometimes provides cleaner and smaller PDFs than other providers.
- Google Books search inside a book is fast. However, see above for why this can result in incomplete searches.
- There is often nothing better available.
Why we should stop when possible
[edit]- WP:AFFILIATE. Commercial book seller vs. non-profit archival library.
- WP:Verifiability. Links that break create problems with verification.
- WP:Link rot. Links should be reliable and stable.
- Lacks Controlled Digital Lending. Free previews are great, but viewing the complete book for free is better.
Alternatives
[edit]- Internet Archive is creating five thousand or more new book scans a day (as of 2023). It is their stated goal to scan every book cited on every Wikipedia. Most of the new books being scanned are modern, but they already have more Public Domain books than Google. More info at Wired Magazine and other sources. Internet Archive is a non-profit library and archive; its URLs and links are significantly more stable and understandable.
- Internet Archive also offers a full text search which is superior to that of Google Books, because it indexes content which is restricted by Google, and because the context of the matches is easier to understand.
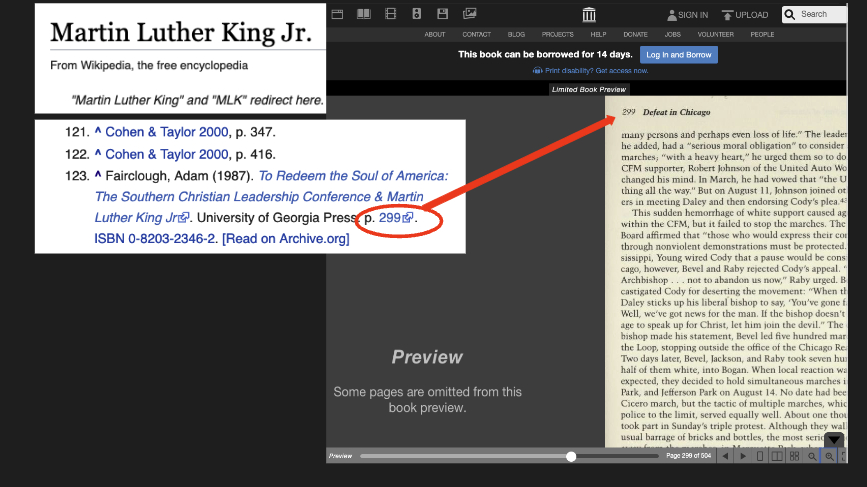
- Internet Archive was sued by publishers. The lawsuit primarily concerns the CDL service which lends books in full. In August 2023, a negotiated judgement was reached. See "What the Hachette v. Internet Archive Decision Means for Our Library", which states: "The Internet Archive may still digitize books for preservation purposes, and may still provide access to our digital collections. We may continue to display “short portions” of books as is consistent with fair use — for example, Wikipedia references (as shown in the image). The injunction does not affect lending [via CDL] of out-of-print books. And of course, the Internet Archive will still make millions of public domain texts available to the public without restriction."
- Hathi Trust is a non-profit archive with stable links. Most of the PD books at Google are also available there, and at Internet Archive.
- Project Gutenberg: As of 20 May 2020[update], this project has over 62,000 items in its collection of free eBooks, created from texts in the public domain.
- Wikisource has over four million articles over 72 languages. All are public domain or freely licensed.
{kind=link}
How to help
[edit]- Search the Internet Archive for books and periodicals: it has over 20 million, comparable in size to Google Books, and it is larger in some collections.
- A simple way to search the Internet Archive via Google or DuckDuckGo:
<search term> site:archive.org(example). Note that Google indexes only a small part of the Internet Archive content. - More in-depth searching: At the https://archive.org homepage, enter a search term into the search box (not wayback machine search, the other search box). Choose the radio button "search inside text".
- A simple way to search the Internet Archive via Google or DuckDuckGo:
- It needs to be easy for the user to link the better alternatives, or to get their links converted and corrected. This is largely a matter of developing the user interface and tools, but the existing wikitext can be improved as well: adding unique identifiers to citations always helps.
- Expand the libraries!
- Internet Archive received millions of uploads by users. Volunteer MediaWiki developers have helped in the past, with BUB.
- Be on the lookout for materials at risk, which you may upload to the Internet Archive. Local newspapers are vanishing very quickly.
- Hathi Trust conducts thorough copyright reviews before they make their copies of books open access: It's No Secret - Millions of Books Are Openly in the Public Domain.
Notes
[edit]- ^ Especially what copyright laws euphemistically call technical measures.
- ^ Giannoumi, G. Anthony; Land, Molly; Beyene, Wondwossen Mulualem; Blanck, Peter (May 31, 2017). "Web accessibility and technology protection measures: Harmonizing the rights of persons with cognitive disabilities and copyright protections on the web". Cyberpsychology: Journal of Psychosocial Research on Cyberspace. 11 (1). doi:10.5817/CP2017-1-5.
- ^ For example the 2010 contract with the Italian ministry.