
Talk:Romanization of Greek/Archive 1
French transliteration
[edit]Hey! The French Transliteration is important for the English Language, too! It's got the reverse pronunciation of Eta and Epsilon from the classical, doesn't it? This is something that is confusing.-Sobolewski 14:22, 31 July 2005 (UTC)
- What do you mean exactly with the French transliteration? Is it for classic Greek? And where is it used in English? Markussep 19:14, 23 August 2005 (UTC)
- It's not important for English, but it's not bad to point out that there will be varying content on this page's international sisters. [Done.] — LlywelynII 03:01, 5 October 2014 (UTC)
nu-tau etc
[edit]Shouldn't it be 7. at the beginning of a word or after consonant 8. after vowel True that nu-tau etc. after consonant appears only in loan words. Andreas 21:53, 12 December 2005 (UTC)
Larissa
[edit]I'm proposing to remove the note about Larissa - I think this is an oddity of this particular name (which appears to have a variant spelling with two sigmas and an alternative English spelling with one s) rather than any indication of a more general rule. --rossb 16:58, 16 January 2006 (UTC)
scientific transliteration
[edit]The article mentions "scientific transliteration", but doesn't define the term. Does this refer to transliteration used in linguistics, or used for scientific naming?
I'm asking because I created an article for scientific transliteration thinking that the term is only applied to a particular system for the Cyrillic alphabet, but then scientific transliteration began to show up for other writing systems, but I haven't found a definition for the term.
The scientific transliteration system for the Cyrillic alphabet is universally used in linguistics, and rarely seen in other fields. The term applies to a specific system, developed in the late nineteenth century in Europe, which has varied very little. Is this the case for Greek scientific transliteration? —Michael Z. 2006-02-17 04:45 Z
Additional comment
This article does not adequately distinguish between transliteration and transcription, where "transliteration attempts to use a one-to-one correspondence and be exact, so that an informed reader should be able to reconstruct the original spelling of unknown transliterated words", and transcription "specifically maps the sounds of one language to the best matching script of another language". (See Transliteration.) I would guess that "scientific transliteration" is the former, but it seems to me to be a misuse of the word "scientific".
For example, of the examples given for Άγιος only Agios is strict transliteration. Ayios and Aghios are attempts to convey the modern greek pronunciation.--Nychtopouli (talk) 00:50, 17 April 2011 (UTC)
- Yup. Replaced. — LlywelynII 09:09, 3 October 2014 (UTC)
Greeklish
[edit]I've added the Greeklish transliteration (all possible versions), since it's so common in written Greek online these days. --Avg 19:31, 5 April 2006 (UTC)
- Thank you, but you needed to provide sourcing and better explanation. See below. — LlywelynII 09:08, 3 October 2014 (UTC)
Square boxes!
[edit]Could somebody please fix the missing letters? I would have fixed them if I had the slightest idea what they were supposed to be. 64.252.100.71 11:48, 1 June 2006 (UTC)
- This is a browser issue. Modern browsers have no problem to display Unicode characters. As a Wikipedian, you might want to use open source software, such as Mozilla Firefox. It might also be necessary to install a Unicode font such as Gentium. Andreas (T) 14:07, 1 June 2006 (UTC)
Greeklish: 3 for xi
[edit]3 for xi: I did a google search for e3o einai and go 3000 hits, mostly Greeklish. It is also mentioned in the Greeklish article. Andreas (T) 13:55, 7 August 2006 (UTC)
Greek online transliteration service
[edit]Adding free online transliteration service for Greek at http://www.latkey.com/translit to the main article as it corresponds to wiki guidelines, is free and don't contain any advertising content, so it makes sense to add it here. —The preceding unsigned comment was added by DanIssa (talk • contribs) .
- It does not matter if it's "free" or "useful". Linking to download sites for Microsoft Office plugins to use the online service of a company is not appropriate. There is no encyclopedic content on the site, and it does promote other products of that comany. If you reference Linksearch: *.latkey.com and the corresponding user contributions, you'll see that there were repeated attempts to place links in several articles, despite all warnings not to re-add them (including the ignored warning on your own talk page). Not only to the transliteration service but also to the company main page, with link descriptions promoting the keyboard stickers. You will not add any more links to latkey.com, i-keyboard.com, or related domains. Femto 13:18, 27 November 2006 (UTC)
"Letters"/"ISO" column?
[edit]What is the status of the column labled "letters", the first of the two under "ISO"? This system looks bizarre. ť or(!?) þ for theta, ķ for chi, p̧ for psi? Who on earth is supposed to use that? And what kind of a "system" is it if it has two different renderings of the same consonant? It's unsourced and certainly not described in our reference for ISO 843. Fut.Perf. ☼ 16:10, 28 October 2007 (UTC)
- P.S.: it was introduced by an anon in July ([1]). It's entirely unsourced and dubious. I guess I'll just remove it. How could such a hoax remain on Wikipedia for so many months and not be challenged? Fut.Perf. ☼ 16:19, 28 October 2007 (UTC)
b/mb
[edit]According to what it says here, μπ should be transliterated as mp or mb on the inside of a word, as in the surname Λυμπερόπουλος, and only rendered as a b at the beginning of a word. Now, the footballer of this name is always given as Liberopoulos. (I note the "greeklish" column makes no mention of placement within the word though.) Now, is that just a personally preferred transliteration that is strictly speaking incorrect (and if so, how is the name actually pronounced - Liberopoulos or Limberopoulos)? Or should "word" in the footnote be "syllable"? Lewis Trondheim (talk) 16:00, 14 July 2008 (UTC)
- Dear Lewis, I 'm greek and I know this is a big problem concerned to the greek names transcription in the latin alphabet! There is the orthographic transcription in which this name should be written as "Lymperopoulos" and there is also the phonetic transcription which is in accordance with the actual modern greek pronunciation. In this case it should be written as "Liberópoulos". Personally I prefer the second way as it makes it clear for people who don't speak greek how to pronounce greek names. Both ways are currently used and this often causes some kind of confusion. But I think we shouldn't try to maintain greek orthography when writing in latin alphabet, because it simply doesn't make any sense to write for example the name for Piraeus in greek as "Peiraias" so that it's closer to the greek spelling "Πειραιάς", while the name is actually pronounced "Pireás". If you notice, IAAF, the international athletics federation writes greek athletes' names totally phonetically, which I think is the most accurate and functional way. I hope I helped! Grecus_magnus
Link moved to talk
[edit]- Online transliteration tool (Greek characters into Latin characters), based on the ELOT 743 (ISO 843) standard - Free php tool hosted on a translation-related website (Lexicon SA Greece).
I can't find the free php tool anywhere.
travb (talk) 02:16, 10 January 2009 (UTC)
- Above link works fine (in Greek). More such links in el:ISO 843. Ageor (talk) 14:22, 5 August 2011 (UTC)
What is Romanization of Greek?
[edit]I added:
- {{Template:context}} <!-- What is Romanization of Greek? -->
To the article, what is Romanization of Greek? Every article should explain what it is first. travb (talk) 02:21, 10 January 2009 (UTC)
Ageor (talk) 14:04, 5 August 2011 (UTC)
Modern Greek romanization
[edit]Our page seems to be at odds with the actual source on the BGN's system. Inter alia, there is no occasion when Greek gamma turns into a -Y- and accented vowels should be marked.
In related news, the ISO system also requires marking accented vowels. — LlywelynII 04:41, 1 October 2014 (UTC)
- Thanks for pointing this out. These mappings have been in the "BGN/PCGN" column ever since the article was created and as such must have been based on this [2] source, which was given in the references back then. However, that source labels the column in question as "BGN/PCGN 1962", whereas the one you just cited says it's from 1996 and supercedes the 1962 one. It also says it's identical with that of the Greek standards organization and the UN, and indeed it seems to correspond to that labelled "UN/ELOT" in our table. So what we ought to do, probably, is just to clarify that the BGN/PCGN column is the older 1962 one. Fut.Perf. ☼ 10:11, 1 October 2014 (UTC)re
- Thanks, but Pedersen goes out of his way to mention that he's not authoritative (specifically for Wikipedia sourcing) and makes at least one error I've seen, where he misses that the ALA-LC also (formally) marks the acute accent. We can link to him in the External Links section but probably should find something better for the actual tables. — LlywelynII 06:20, 2 October 2014 (UTC)
- Since you're here and paying attention, though, I corrected all of the "scientific" [sic] transliterations to the formal system they were claiming to be sourced from (the ALA-LC). I'm sure there are other systems that do transliterate chi as kh, though, if you have time to go find one so we can include it. — LlywelynII 06:22, 2 October 2014 (UTC)
Citation
[edit]The article could use more cites, particularly
- a better source for the 1962 US standard and
links toa better source for the original Greek format (ELOT 1st ed.) that was adopted by the UN in 1987, but also for some minor things like the examples we're using for Greek text messages.
On the other hand, remember WP:BLUE: we don't need to provide OED sourcing for individual words in the intro definition. Sourcing for "romanization" (the word itself) belong at romanization and sourcing for "Greek" (the word itself) belong in the etymology sections of Greek and Greece's various pages. Combining sourced definitions for individual words would count as WP:OR anyway... What could work would be if we had a link to someone else discussing Greek romanization and its problems in a scholarly context. I'm sure there's something like that out there, for those editors with JSTOR or NEXUS access. — LlywelynII 10:19, 2 October 2014 (UTC)
Also,
- Sourcing for the "classical" Latinate transcription
- A modern transliteration system for Ancient Greek that uses kh for χ. I know they're out there somewhere...
— LlywelynII 02:51, 5 October 2014 (UTC)
Here is one transliteration system which uses kh: Hellenion, a Hellenic polytheist organization: http://www.hellenion.org/calendar/
quote: "Transliteration of Greek month names and festivals below used “y” to represent the short “u” of Greek, “kh” is used to represent “chi” (χ)," Traversetravis (talk) 19:11, 15 July 2017 (UTC)
Greeklish removal
[edit]I'm going ahead and removing all of the Greeklish from the tables. It should be covered (either here or at Greeklish) but:
- The terms need to be explained: I think "iconic" indicates "visual", but what is the difference between "simple" and "English" phonetic or between "keyboard" and "spelling"?
- I believe this is probably common enough to be notable, but we need to provide sourcing. I can find links to Baloglou's "Byzantine" system, but it's not mentioned here and how common is it in Greek?
- The Greeklish forms of the vowel and consonant clusters and digraphs is a mess: they need to be sorted and (especially not knowing what the categories even mean) I'm not the one to do it.
Kindly address these concerns before restoring the Greeklish. — LlywelynII 09:18, 3 October 2014 (UTC)
Hi, User:LlywelynII. I've only now saw your message. Since I am the one who had originally added the Greeklish columns in the table back then I should clarify what each system means.
- Greeklish systems
- Iconic system: Is when you use Latin characters that have, as correctly said, a visual resemblance to the Greek ones. For instance, Greek "Θθ" (theta) is substituted by number "8".
- Phonetic system: In contrast to iconic/visual system, this one uses Latin characters of which the sound matches the sound of the Greek ones. It has two very common variations:
- English phonetic system: When you write the sound of a letter as an English/American/Australian/etc would write it. For example Greek "Γγ" (gamma) is substituted by "gh" in an effort to get closer to "Γ"'s sound which is softer than "G"'s. Or, another example, in Greek, "Σσς" (sigma) always sounds as "ss" (as in "soft"), not as "z" (as in "cheese"). So if you write the Greek name "Τάσος" as "Tasos" most English speaking people will read it "Tazos" so you write it "Tassos".
- Simple phonetic system: When you write the sound of a letter in a more general way, not strictly English. As a Chinese/Mexican/Egyptian/etc would write it. For example Greek "γ" is substituted by plain "g". Note that "g"'s sound in Greek is written "γκ". So "γ" and "γκ" are both "g"s in this system! All vowel variations get one letter for example, all "I"'s, i.e. Ιι,Ηη,Υυ become "i". All "E"'s (even combinations like "αι") become "e". This is the most used system of all, espessially among young people. Women tend to use this too.
- Keyboard system: This one is most weird. Is when you write Greek as if your (QWERTY) keyboard was switched in Greek while actually the keyboard is switched in English!!! The funniest thing about it is that this system is officially used by the Greek Army!(!!!!) So the Latin characters produced by this have neither a visual nor an aural resemblance to the original Greek ones. For example, the Greek letter "Θ" (Theta, sounds like th as in thorough) is written "U".
- Spelling system: I left this for last because is not an one-to-one transliteration method but it's more of a general rule. Is when you write Greeklish (in any of the above ways but) in a strict way according to Greek grammar, and in which reversal to Greek is possible. For example, if a Greek word has two "σσ" then you should write two "ss", not one. But the most notable example is the combination "γκ" which is the sound "g" in English (as in "go") that is written as "gk". Same for "γγ", also a "g" that is written "gg". This system is mostly used in conjunction with the iconic system but sometimes you may see it used with other ones too.
- Notable? Oh yes! It's how almost half of the Greek people write on the Internet!
- Sources Yes, of course it needs those but on the other hand all these are common knowledge to Greeks. It's something you see every day, every second actually, on Facebook. About the classification, I remember reading about it somewhere and planning to add more stuff and sources but then I got busy and totally forgot about this article till now.
- "The Greeklish forms of the vowel and consonant clusters and digraphs is a mess". Now you know how it's like to be Greek and try to read what your fellow Greeks write on the Internet! ;)
--Protnet (talk) 00:03, 22 January 2015 (UTC)
A few sound examples
| Greek | Greeklish | ||||||
|---|---|---|---|---|---|---|---|
| Iconic | Phonetic | Keyboard | Mix (very common) | ||||
| Simple (very common) |
Extreme (very rare) |
Simple (very common) |
English (common) |
Simple (Army/TELEX) |
Extreme (rare) | ||
| Είσαι καλά; ("Are you ok?") |
Eisai kala; | Ise kala? | EISAI KALA? | E;isai k;alaq | |||
| ξέρω ("I know") |
3erw | 3epw | ksero / xero | JERV | j;erv | kserw | |
| Θανάσης (male name) |
8anashs | 8ava6ns | Thanasis | Thanassis | UANASHS | Uan;ashw | 8anasis |
| Άγγελος (lit. "Angel", also a male name) |
Aggelos | Ayyelos | Agelos | Angelos | AGGELOS | ;Aggelow | |
| Ευθυμία (a female name, lit. "cheer, gaiety") |
Ey8ymia | Eu8umia | Efthimia | Euthymia | EYUYMIA | Eyuym;ia | Eu8ymia |
| Μπάμπης (male name) |
Mpamphs | Babis | Bambis | ||||
--Protnet (talk) 12:19, 22 January 2015 (UTC)
Beta code
[edit]Beta code is an encoding used in TLG files to allow keyboarding of Greek on all-uppercase Latin keyboards -- but it was surely never intended as a transliteration for human use, nor is it ever actually used as such. I would be shocked to see it in any published material. Can anyone point to a use of Beta code besides in TLG texts (as used by Perseus for example)? If not, I don't believe it belongs in this article. --Macrakis (talk) 14:17, 3 October 2014 (UTC)
- Any particular reason not? It's a notable, sourced form of Greek romanization. We shouldn't be attaching undue weight to it, but I don't see the harm caused by its inclusion on the side of our tables. We're not a print encyclopædia: we can afford some lagniappe. — LlywelynII 16:01, 3 October 2014 (UTC)
- I do think it's interesting enough to be included here, but I also see Macrakis' point about its fundamental difference from the other schemes. It's not "romanization" in the sense of a mapping into Latin characters for use in actual, human-readable Latin-script text, but only intended as either an internal computer encoding (and as such invisible to the human reader) or as a makeshift technical substitute. My personal preference would be to keep it in but have more of an explanation of its fundamentally different role in the introductory text. Fut.Perf. ☼ 08:21, 4 October 2014 (UTC)
- I kind of like the flow of the intro as it is. Sentence at the end of the 2nd paragraph? or just an explanatory footnote beside its sourcing in the charts? — LlywelynII 02:40, 5 October 2014 (UTC)
- I do think it's interesting enough to be included here, but I also see Macrakis' point about its fundamental difference from the other schemes. It's not "romanization" in the sense of a mapping into Latin characters for use in actual, human-readable Latin-script text, but only intended as either an internal computer encoding (and as such invisible to the human reader) or as a makeshift technical substitute. My personal preference would be to keep it in but have more of an explanation of its fundamentally different role in the introductory text. Fut.Perf. ☼ 08:21, 4 October 2014 (UTC)
Google Translate
[edit]Particularly given how often its system is going to be copied over here, does anyone know what it is? It looks kind of like the outdated ELOT or (presumably still-current) UN system, using macrons below instead of macrons above: ⟨Όρων Χρήσης⟩ is given as ⟨Óro̱n Chrí̱si̱s⟩ instead of ⟨Oron Christis⟩ or ⟨Órōn Chrī́sīs⟩. It also (only sometimes?) includes a macron below on final sigmas, which isn't a part of any formal system I've seen. — LlywelynII 03:38, 4 October 2014 (UTC)
... And now that I've asked, I can't get it to recreate that effect (see the macronless sigma above). Maybe it's only for certain words? or was a glitch? — LlywelynII 03:49, 4 October 2014 (UTC)
- The goal seems to be to make the letters completely specify the pronunciation, and to use diacritics to represent the spelling, that is, to make it reversible. The underbar appears to mean "alternate form":
- ι/η = i/i
- ο/ω = o/o
- final ς/final σ = s/s -- final σ is rare
- non-final or isolated σ/non-final or isolated ς = s/s -- isolated ς is rare
- αυ/ευ/ιυ = af/ef/if -- to show that the f represents υ, not φ
- ... and there is one more convention:
- γγ/νγ/γκ/νκ/γξ/νξ/γχ/νχ = ng/n'g/nk/n'k/nx/n'x/nch/n'ch
- ψ/πσ = ps/p's
- I don't know if this is documented anywhere. --96.233.22.128 (talk) 21:15, 11 October 2014 (UTC)
New tables
[edit]I have a few gripes with the recent changes by User:LlywelynII, though there is unoubtedly a lot of positive effort in them [3]. I'll leave any matters about the new text passages aside until we have hashed out the related issues at Talk:Greek alphabet; for now, I'd just like to address the table layout. The main table for Modern Greek has become huge, with around 60 or so rows and 14 columns, making it well wider than the normal text window on my machine. For purely practical reasons of reader-friendliness, can we please think about ways to condense this?
- First thing, is there a reason we need the parallel pairs of columns for upper and lower case? As far as I can tell, there aren't any non-trivial differences between upper and lower case transcriptions; the only differences shown in the table are a few cells where the upper case is empty, but that is purely because these are letter combinations that are supposed not to occur word-initially, a fact that doesn't actually have to be specified as a separate rule of transliteration but is simply a contingent fact about the language. (Also, if you were to transliterate text in ALL CAPS, you would still transliterate word-medial "ΓΧ" as "NCH" etc., so those rules aren't in fact case-specific as currently suggested).
- Secondly, there are a couple of entries where the Greek letter cell has been vertically divided for separate font variants: β/ϐ, ε/ϵ, θ/ϑ, κ/ϰ, ρ/ϱ,
 /
/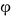 . I believe this is quite unnecessary here. As described in Greek alphabet#Glyph variants, these are essentially purely stylistic glyph alternates on the font level. The difference between "ε" and "ϵ" or between "θ" and "ϑ" is no more linguistically significant than that between a Roman looptail "g" and an open-tail sans-serif "g" in Latin. They are the same letter, and thus there is no reason at all why any reader should expect different transliteration rules for them. The fact that some of these character variants happen to have separate encodings in Unicode is quite orthogonal to any transliteration issues: these extra characters are meant purely for the encoding of technical and mathematical symbols, where the glyph difference happens to be significant; since these Unicode characters are never intended to be used to represent Greek text in the first place, there is never an issue of transliterating them either.
. I believe this is quite unnecessary here. As described in Greek alphabet#Glyph variants, these are essentially purely stylistic glyph alternates on the font level. The difference between "ε" and "ϵ" or between "θ" and "ϑ" is no more linguistically significant than that between a Roman looptail "g" and an open-tail sans-serif "g" in Latin. They are the same letter, and thus there is no reason at all why any reader should expect different transliteration rules for them. The fact that some of these character variants happen to have separate encodings in Unicode is quite orthogonal to any transliteration issues: these extra characters are meant purely for the encoding of technical and mathematical symbols, where the glyph difference happens to be significant; since these Unicode characters are never intended to be used to represent Greek text in the first place, there is never an issue of transliterating them either. - While we're at it, we might also consider the extra rows for medial and final sigma (σ/ς). Now, this difference is somewhat more significant than the others, but since none of the Romanization schemes listed actually distinguish between them, the rows could easily be merged without loss of information.
I'm still a bit on the fence whether I like the general idea of merging all the digraphs together with the single letters into a single table, but before I consider that further I'd really like to see the whole thing visually reduced to something more manageable. Fut.Perf. ☼ 17:17, 12 October 2014 (UTC)
- I strongly agree with FP's comments. It is ridiculous to include capital and small and variant glyphs in these tables. --Macrakis (talk) 19:33, 12 October 2014 (UTC)
- As below, I strongly disagree with leaving out the most common variants (phi, kappa, theta) that are people are going to run into frequently as they're trying to romanize Greek. On the other hand, a quick glance through romanization of Russian, Chinese, Korean, and Coptic does support the idea that (regardless of ELOT's formatting and presumably the ISO's) Wikipedia usually doesn't bother giving the capital Latin forms. Of course, I don't believe any of those languages have the hinky issues created by Greek's consonant digrams, but then maybe the consensus will be to split that back out anyway. — LlywelynII 21:45, 12 October 2014 (UTC)
- Heya. Initial response:
- There's a case to be made for the compression of the upper- and lower-case forms. It does make it more concise and there are some sources—like the UN—which don't distinguish them, but
( a ) The most thorough do list the capital forms distinctly. The prior version of this page did, as well: it just gave capital Greek forms and then misleadingly ignored them in the romanization section. It didn't use columns either, but columns don't per se add to the width as implied by Fut. What does is the larger, more user-friendly size of the text, the clarifying white-space padding, and the additional footnotes. I obviously find these to be more helpful rather than less. As none are mentioned above, presumably Fut. feels the same.
( b ) There are several entries where the capital has a single romanization while the lower-case forms have more. There's the fact that the present Greek ligature ᾼ became the Latin ligature Æ before but is now two Latin letters Ai. There's the fact that the ELOT source material specifies that capital Θ should be romanized TH which could mislead people into thinking the name Θεόδωρος should be romanized THeódōros when in fact it shouldn't. You're right that ALLCAPS forms are going to use the medial forms; if I hadn't mentioned that yet, apologies, but it wasn't mentioned in the prior form of the page either and I'm not finished with the charts. (If you include the ALLCAPS form in the chart, meanwhile, you need a separate note telling people that Θ-followed-by-a-lower-case-letter should be romanized as Th instead. I think the present version is better.)
Another thing to mention, if you're adding the text, is that capital and some ALLCAPS forms of the letters take accents but other forms such as acronyms don't.
( c ) It would be better if I (or someone) could find a way to remove the internal borders within a letter. (The lines, e.g., between the A and a forms of the letter and between A, Ai, and Au.) I tried transparent borders and borders =0px but those commands don't seem to work. Once I find out how to do that, the duplicated footnotes (e.g., for Αυ) could be placed just on the second set. That will compress the width by about the space of 2 columns.
( d ) Apart from that, there are minor tweaks that would help around the edges: "notes" was shortened to "n. " but could be further compressed to "n". The padding could be compressed from 1em to 0.5em for each column.
( e ) That said, there were 12 columns before and—zomg—14 columns now. It's not "now" "unwieldy" or "huge" and (while the tweaks above are things we can do) the more legible font size and white space are improvements. The table should scroll correctly; those who don't like scrolling (presumably including Fut.) can zoom their browser out. The only problem would be if there were unpleasant textwraps at smaller resolutions; I tried to use nowrap tags and to avoid that but would be happy to correct any lingering mistakes. - We're not talking about linguistic variants. They're included vertically and without division because they are character variants. They happen to be variants that do not look (in some cases) at all like the other form and we should include them here. People come to this page to see "what is this thing?" "what does this look like in letters I understand?" They come here because they have Greek text in front of them and are trying to romanize it. We should help those people, not just ignore them because we understand better. (This is quite apart from completely bizarre forms or archaic variants: we can't be too cluttered. Those archaic forms of b aren't important. If you feel even the cursive b is too uncommon to bother with, that may be valid. But I've certainly encountered students who've run into cursive theta or kappa and had no idea what they were looking at. Both are certainly common enough we should show what they are and what they map to. Ditto the two different forms of phi, which some people won't be able to figure out on their own because Unicode treats them as a single glyph: people usually only see one or the other on their computer although both appear in print.)
- By "extra rows", I presume you mean the line between them? As above, we should ideally remove those borders, at which point it's moot whether we're formatting it as rows or as text line with a break. We shouldn't just have a misleading or conflating single s.
- There's a case to be made for the compression of the upper- and lower-case forms. It does make it more concise and there are some sources—like the UN—which don't distinguish them, but
- Again, I would like to hear from other editors apart from just you. I'm busy now, but probably you can play around with things, I can tweak things, and maybe by this weekend we can do a RfC on the things where we just have differences of opinion and hopefully get some more thoughts in here (edit: Hi, Macra!). I think the margins and unification of some of the footnotes will bring it back around the same width as the former chart, which is your underlying problem. The chart certainly looks better than it used to and is more helpful for having more information more simply and easily formatted. — LlywelynII 21:38, 12 October 2014 (UTC)
Just a small technical clarification question, because I found myself thoroughly confused by something you seemed to say: when you say "the present Greek ligature ᾼ" above, and in the entry "ᾼ" in the second line of your table, are you actually seeing (or intended to see) a capital alpha with a iota next to it? If yes, my question may seem daft to you, but what I'm actually seeing here on my screen is a capital Alpha with a iota subscript. You must have selected U+1FBC "Greek capital letter Alpha with prosgegrammeni", which is intended to be the capital equivalent of "ᾳ", and may render as either a capital Α with a iota subscript beneath it, or as A with a full-sized iota at the right, depending on your font. What you really want when you're talking about the "αι" digraph (or ancient diphthong) and its capital equivalent is the two standalone letters, "Α"+"ι". Fut.Perf. ☼ 22:21, 12 October 2014 (UTC)
One more point about the treatment of capitalization: if you really wanted to capture all of the combinatorial possibilities, there'd be no end to it, and it would definitely not fit into a table. Consider that we have to treat capitalized, non-capitalized, and all-caps words; that each digraph can occur in Greek in three constellations (ΕΙ, Ει, ει); that each single Greek letter that is romanized as a digraph will likewise have three mappings (Χ=CH, Χ=Ch, χ=ch); and that there's still the issue of initial "h" in vowels with rough breathing (if you have a capitalized Ἁ, it's not actually the vowel letter that is capitalized in the Romanization, but the preceding "H"), so we'd need at least three extra entries for each such vowel (Ἁ=HA, Ἁ=Ha, ἁ=ha). – There is one extremely simple solution to all this: simply recognize that Romanization and capitalization are completely orthogonal to each other. When you Romanize a Greek word, you apply a single set of letter mappings, independently of letter case, and then you re-apply capitalization on the resulting Latin string, again independently of what mapping each letter comes from. As such, the casing distinctions are quite extraneous to the table. Fut.Perf. ☼ 09:11, 13 October 2014 (UTC)
- There is no reason for us to slavishly follow ELOT's documentation practices. They are a standards organization writing technical documentation, we are an encyclopedia writing for the general reader. Our goal should be to be clear and comprehensive for reasonable readers.
- The handling of iota subscript with capitals (like the handling of Dutch initial IJ, say) is exceptional and can be handled exceptionally. There is no reason to pedantically fill out a table with unexceptional cases like TH (all-caps) / Th (initial caps) / th (small) and A/A/a. Adding columns which are almost entirely redundant makes the article less, not more, clear.
- There is no reason for us to show glyph variants in the transliteration table. There are also variants for Latin, e.g., a/ɑ, g/ɡ, s/ſ. It would be ridiculous to show both variants whenever the Latin alphabet is displayed — and in fact we don't. --Macrakis (talk) 18:33, 13 October 2014 (UTC)
I've been trying to re-work the table (editing it off-wiki) so as to visually condense it, cut some of the excess weight but otherwise preserve most of the basic layout, but after several hours fidgeting with wikicode, I am despairing of the complexity. At this stage, I'm also getting the feeling that some of the details that are causing so much complexity are not quite right. Especially, there's the thing about the case distinction between the canonical digraph values of ΑΥ, ΕΥ, ΟΥ, ΑΙ, ΕΙ, ΟΙ on the one hand, and the exceptional "hiatus" readings (i.e. where there is an accent on the first, and/or a diaeresis on the second element). Currently, the table suggests that only a few of the transliteration schemes distinguish between these (see the extra rows for "Standard" and "UN" marked with "n.4"), but not others (e.g. "ELOT", "ISO" etc.). Moreover, no such distinction at all is marked for "ΑΙ". Surely this can't be right. No reasonable transliteration scheme could possibly render "Ταΰγετος" as "Taugetos" or even "Tavgetos", and not even the "obsolete" BGN phonological mapping of "ΑΙ">"e" would have rendered "τσάι" as "tse". This is really a universal precondition for all proper treatments of Greek: if the letters are not being used as diagraphs, then the diagraph rules don't apply to them. If our sources are found to not spell out this basic rule explicitly for each of these schemes, then I strongly suspect that's really just a matter of insufficient sources. Note that for some of these we haven't really been able to look up the official statement in the original publication.
I'm more and more leaning towards taking the whole table apart again, with a first basic table just for the individual letters, and separate ones for vowel and consonant combinations, where things that belong together can much more easily be treated together and explained with surrounding text. Fut.Perf. ☼ 19:43, 13 October 2014 (UTC)
I only have expertise in Ancient Greek, so I will offer my comments on the Ancient Greek table. I think, like Fut.Perf., that the uppercase forms are unnecessary. The asterisk in Beta Code and the complexities of capitalizing digraphs could be more simply dealt with in a few paragraphs below the table. I would also like to return to listing the romanization of αι and οι as ae and oe; the ligatures æ and œ are from Medieval Latin, in which the Latin diphthongs had become monophthongs identical to e, and are not as often used in modern editions of Classical Latin texts, now that the Classical pronunciation has been more correctly reconstructed. We could include a note saying that the ligatures are essentially equivalent and are used in some forms of Latin and in Latinized Greek loanwords in some modern languages, but they should not be enshrined as the primary romanization. — Eru·tuon 20:07, 13 October 2014 (UTC)
Classical transcription of X
[edit]As a complete amateur, I'm reluctant to make any substantive edits, but surely the Classical transcription of X (chi) is Ch, not Kh. It may be Kh of Library of Congress, American Library Association, etc. — Preceding unsigned comment added by 70.66.183.64 (talk) 15:47, 9 May 2018 (UTC)
- Indeed, thanks for spotting this. This error was introduced in a recent undiscussed edit that unfortunately slipped through [4]. Incidentally, the Library of Congress source also uses "ch". Fut.Perf. ☼ 17:48, 9 May 2018 (UTC)