
Talk:Extended precision
| This article is rated B-class on Wikipedia's content assessment scale. It is of interest to the following WikiProjects: | |||||||||||||||||
| |||||||||||||||||



Hyperprecision
[edit]I was surprised to see no discussion of software that provides hyperprecision, so I added a section that I hope isn't "original research", referencing Knuth's SEMINUMERICAL ALGORITHMS. I decided not to mention that Nash, in my direct experience, was working in his recovery on software for hyperprecision, since this doesn't appear in the major source for Nash. I'd described it in my letter to Sylvia Nasar as one of her sources but this doesn't appear in her book (A Beautiful Mind).
58.153.108.144 (talk) 14:41, 18 May 2008 (UTC) Edward G. Nilges
- Hello Edward. I think the Arbitrary-precision arithmetic article is one that contains information similar to what you have added here. -- Tcncv (talk) 15:25, 18 May 2008 (UTC)
- I propose removing the entire Extended precision#"Unlimited" precision section from this article, since it is off topic and mostly covered by the Arbitrary-precision arithmetic article. If there is any useful content that should be retained, it can be merged into that article. Opinions? -- Tcncv (talk) 02:33, 19 May 2008 (UTC)
- Seems reasonable; I was a bit surprised to see the introduction of multiple-word precision here as it is covered elsewhere. "Extended precision" seems to me to be restricted to the limited extension (in odd ways) of an existing precision, as with the 64-bit to 80-bit format, or as with the IBM1130, not the extension to perhaps hundreds of words. The hyperprecision addenda could be used to modify the Arbitrary-precision arithmetic article.NickyMcLean (talk) 03:33, 19 May 2008 (UTC)
- I agree that any information on arbitrary precision should go under arbitrary-precision arithmetic. The term "extended precision" in current technical usage refers almost exclusively to special support (usually in hardware) for a specific precision slightly larger than double precision, not to any arbitrary increase of precision. —Steven G. Johnson (talk) 04:49, 19 May 2008 (UTC)
- I can see how this term would be confusing to people. I have added a new section to clarify the difference (although the wording should be improved!). Does everyone agree with this addition? -- intgr [talk] 15:58, 19 May 2008 (UTC)
- I added a few more links to the some of the other floating point precision articles (half precision, single precision, double precision, and quadruple precision) and to the particularly informative Floating point article. In comparing the articles, this one is very different from the others, and I think it might benefit from adapting some of the content patterns from the others. -- Tcncv (talk) 03:27, 20 May 2008 (UTC)
NickyMcLean: I have no problems with your refactoring in general, but I am not sure about what are you trying to say about arbitrary-precision arithmetic.
- "By contrast arbitrary-precision arithmetic refers to implementations of much larger numeric types with a storage count that usually is not a power of two"
This seems to be implying that non-power-of-two formats fall under arbitrary-precision arithmetic? However, 80-bit floats, which is an extended precision format, is not a power of two.
I think the line should be drawn between "extended precision" meaning FPU-constrained-precision floats and "arbitrary-precision" for cases where the precision is only limited by available system memory. Or is there a problem with this dichotomy? -- intgr [talk] 14:43, 20 May 2008 (UTC)
- Poorly phrased then. But remember that the distinction should not be based on what the FPU offers, because some computers do not have a FPU at all for floating-point arithmetic and it is supplied by software (using integer arithmetic operations). Similarly, although binary computers are dominated by powers of two in storage sizes now, the PDP something-or-other used an 18 bit word, the B6700 used 48 bits (actually 53 with tags and parity; I was told that this was something to do with conversion from an existing design for telephone exchanges) and of course, the decimal digit computers such as the IBM1620 used N decimal digits, though with certain limits: no more than 100 digits and a two digit exponent for its hardware floating point, looser constraints for integers. The B6700 did offer single and double precision and it did require one or two words in the usual powers-of-two style. So it seems that I mean that "sizes in powers of two" applies to standard arithmetic ("half", single, double, quadruple being one, two, four, or eight storage words though the word size need not involve a power of two bit count) and that extended precision steps off that ladder, while arbitrary precision employs some count with no particular limit other than storage access details.NickyMcLean (talk) 20:51, 20 May 2008 (UTC)
- You're right, it's less clear than that. I'm out of ideas. -- -- intgr [talk] 23:27, 22 May 2008 (UTC)
- While they may not always be supported in hardware if an FPU is not present, it should be accurate to say that the extant "extended precision" types were designed based on the constraints of hardware implementations. e.g. apparently the most common extended precision type is the IEEE 80-bit extended-precision type, which is directly based on the format used by the 8087 hardware, even if some implementations of this type may be in software. —Steven G. Johnson (talk) 01:56, 23 May 2008 (UTC)
IEEE standardization
[edit]I see the statement that the 80 bit format is in the IEEE standard, but I am looking at the IEEE 754-2008 Standard section 3.1.1, and I see as "basic formats" only binary 32, 64, and 128, and decimal 64, 128. Binary 16 is defined as an interchange format. Section 3.7 discusses extended precision in the abstract, with no specific mention of 80 bit precision. I can't see specific mention of the acceptability of the explicit first significand bit that is a feature of the 80-bit format. So I think the statement that the 80 bit format was standardized by the IEEE standard is false and should be removed. — Preceding unsigned comment added by Matthew.brett (talk • contribs) 23:59, 15 October 2011 (UTC)
This is incorrect-- the IEEE 754 standard recommends that an extended precision format be included and gives minimum requirements for precision and exponent and the 80-bit format was explicitly designed to meet the IEEE-754 requirements (note: because it is a high precision format only intended for storing intermediate results, and not interchange, its exact format does not need to be specified in IEEE754). I have added a sentence to the text discussing this. Brianbjparker (talk) —Preceding undated comment added 18:50, 19 February 2012 (UTC).
- Actually - the x86 80-bit format was designed well before the IEEE 754 standard was developed. The 8087 was designed in the late 70s while work on the IEEE standard didn't start until after design work on the 8087 was well under way and the IEEE standard wasn't published until 1985. That the IEEE standard was heavily influenced by the 8087 design is a tribute to the care that Intel's engineers applied to designing the chip. I suspect that the 8087 was almost IEEE compliant even though it was being sold 5 years before the original standard was approved. On brief review, it looks like the only mandatory feature the 8087 didn't support was the distinction between signalling and quiet NaNs.
- Bill 18:17, 22 February 2012 (UTC)
- Well, yes the final standard publication was delayed somewhat, but the key point is that both the x87 implementation and the IEEE-754 standard proposal were developed together by Kahan and others in a multi-vendor standard, as opposed to, for example, IEEE-754 just later standardising existing practice of the x87 (the link http://www.cs.berkeley.edu/~wkahan/ieee754status/754story.html has some nice insights into the history by Kahan himself). Brianbjparker (talk) 22:16, 22 February 2012 (UTC)
Note: When editing it is important not to remove the information that 80-bit x86 format is an IEEE-754 double extended format (in fact one of the three most common IEEE 754 formats)- This is widely misunderstood amongst programmers and therefore leads to its disuse because of incorrect concerns that it is not a standard format. Brianbjparker (talk) 03:34, 22 February 2012 (UTC)
- This is really a question of semantics. The x86 80-bit format is compatible with the requirements of an IEEE extended double precision format however it is not one of the IEEE formats. The 1985 version defined two binary formats: the 32-bit single precision and the 64-bit double precision version. The 2008 version of the standard adds a 128-bit quad precision format. One of the key requirements of a "format" definition is a detailed description of the interpretation of each bit. The IEEE standard does not provide this level of detail for an 80-bit format.
- As a programmer, I need to know in complete detail the meaning of each bit. You can not hand me 80 bits and a copy of the IEEE 754 standard and expect me to correctly interpret the value. For example, the x86 format has an explicit integer bit. Upon reading the standard I might incorrectly assume that this 80-bit format also had an implied integer bit and interpret the value to be twice what is really is. Both the explicit and implicit integer-bit versions would qualify as IEEE 754 compliant extended double precision implementations of an 80-bit format.
- This is why I labeled the format the "x86 Extended Precision Format" rather than the "IEEE 754 Extended Precision Format". There are a large number of bit encodings that satisfy the requirements for an IEEE 754 Double Extended Precision value. The Motorola 68881 also has an 80-bit format that satisfies the IEEE requirements extended double precision format however the bit layout is different.
- There is no question that this is an important format however its significance stems from the ubiquity of the x86 architecture combined with Intel's willingness to share the details of the format.
- Bill 18:17, 22 February 2012 (UTC)
- Both the 1985 and 2008 versions of IEEE-754 indeed precisely specify the minimum precision and range of the extended formats (as well as the other requirements for NaNs etc for an extended format to be IEEE-754 compliant) and indeed *explicitly recommend* that such extended versions of the base formats be included. You are not distinguishing the different roles of the interchange formats (which must be precisely specified at the bit level) and purely computational formats such as double extended in which only minimal precision/range requirements need to be specified as double extended is only intended to be used for scratch variables within computations. In all the relevant literature, including for example the reference I cite where Kahan-- the primary designer of the IEEE-754 standard and x87-- explicity lists the double extended as part of the IEE-754 standard formats. Brianbjparker (talk) 22:16, 22 February 2012 (UTC)
- I support Brianbjparker's comments. IEEE-754 gives minimum requirements for an extended basic floating point format. The basic format have a specified bit encoding for interchange; the standard does not require a bit encoding for extended formats. An IEEE format does not require an encoding. Glrx (talk) 00:07, 2 March 2012 (UTC)
A note on the reason for the long-winded explanation of precision loss
[edit]Precision loss is a complicated subject. However in typical situations such as the multiply-add loops in matrix multiplication or polynomial evaluation it builds up slowly over many iterations. The IEEE standard is designed to reduce rounding error to less than 1/2 units in the last place for any calculation. Furthermore individual operations will generally round up or down randomly so the combined result of many operations will tend to be close to the value that would have been computed had rounding not occurred. So the question is: why would Intel add 12 bits to the significand when it would seem that 3-4 might be sufficient? At the time that the 8087 was being designed, transistors were expensive and memory was limited to 1MB so it would seem that Intel would have an incentive to keep the size of registers as small as possible.
It turns out that exponentiation is a worst-case scenario. In contrast to multiply-add loops where it might take thousands of operations for precision loss to become noticeable, a single exponentiation operation can suffer from significant precision loss unless the intermediate results are stored with sufficient precision. Furthermore exponentiation requires 12 additional bits in the significand to avoid precision loss.
The previous version of this article speculated that the 64-bit significand was chosen because the 8087 already had hardware that could perform 64-bit integer arithmetic and "...With trivial additional circuitry, it could therefore be generalized to perform floating-point arithmetic." The book The 80286 Architecture was written by Intel engineers involved in the development of the 8086 and 80286 and provided a far different explanation. This is the only reference I have found that explains why 64 bits are needed. Most other references simply have a vague statement saying that the added bits are to improve precision.
Because this provides some historical context to the design and because programmers might use exponentiation on 80-bit numbers without being aware that similar precision-loss issues apply to this precision as well, I thought that this would be an appropriate topic. Bill 18:17, 22 February 2012 (UTC)
- The general approach to precision questions when evaluating functions is to write f(x±eps) = f(x) + f'(x)*eps, and for f(x) = exp(x), f'(x) = exp(x) as well, thus for positive x, an uncertainity in the value of x is multiplied by the value of exp(x), a much larger number. Accordingly, to evaluate exp(x) in double precision with uncertainity in the low-order bit of x, to a value likewise with uncertainity in only the low-order bit of the result, still greater precision is needed. For example, exp(10.000) = 22026.46579, and exp(10.001) = 22048.50328 a change of 22 as expected: 22.026*0.001. A variation in the fifth digit of x produces a variation in the fourth digit of the result. Calculation with five-digit precision would at each step introduce additional variation of the same size though the actual behaviour would depend on the actual computation, and your description offers such details, to the degree of a specific requirment being derived.
- The announced goal or even requirement that f(x) be evaluated so that only its last bit is in doubt is of course of merit (especially considering the alternative!) and indeed, the introduction of calculation error as a calculation proceeds should be minimised, but, the likes of exp(x) show that conformance to this goal should not be taken as meaning that the result is truly accurate to the last bit even though it is computationally. Thus, although exp(10.001) is indeed 22048 and that low-order digit is correct for that explicit value of x, this does not mean that given x, 22048 is the true value of exp(x) to the last digit. Another example might be provided by arctan(pi) - as a floating-point number, pi cannot be represented, but (ignoring overflow) arctan(pi) might well be correct to the last bit for that (incorrect) floating-point value of pi.
- In the case of the IBM1130 (as a non-intel example), the hardware did have a 32-bit integer divide operation, and given that, arranging a 32-bit floating point significand for extended precision (three 16-bit words) was straightforward. Indeed it was the 32-bit floating-point arithmetic that was annoyingly messy as the same 32-bit integer divide was employed, but now the 8-bit exponent part had to be removed from the 32-bit register.NickyMcLean (talk) 20:48, 22 February 2012 (UTC)
- This is an interesting approach. In this case, the function is: . However the intermediate result in question is . I think the question is: For all representable double precision numbers x and y where x>0, how many bits of precision must g(x,y) be calculated to such that 2g(x,y)±eps doesn't affect the result. My calculus is way to rusty to try to differentiate this. It would be interesting to see where this goes. --Bill 22:02, 22 February 2012 (UTC)


- I have not had the chance to read the reference you cited yet, but I think the problem with the current wording is that it confuses the high level design aims of double extended with technical decisions on its precise format, and thus gives the impression that double extended is some sort of kludge and not a major design aim. I have added a quote by Kahan clarifying that double extended was needed and provided to provide additional precision to avoid loss of precision due to roundoff for *all users*, not just for Intel's requirements in designing its exponentiation library. So ideally the precision of double extended would be set as large as possible but implementation issues limited that. The exponentiation example you give is indeed a good example of a computation demonstrating why a *minimum* precision of 80-bits is needed (though see comment above), but the engineering decisions setting its *upper* limit are unknown to me but are probably closer to the original version and due to 64-bit data paths being available for the mantissa etc. But the main point is that in the article, the high level design aims-- to provide an extended precision to be used to avoid accumulated round-off in any double precision computation -- are not obscured by focussing on detailed engineering decisions in its implementation (though those are interesting and may be worth discussing in the article). I think the quote by Kahan I added gives this higher level context. Brianbjparker (talk) 22:16, 22 February 2012 (UTC)
- This is the "tablemaker's dilemma". Suppose you are preparing a table of the values of a function, at some specified values such as 3.0, 3.1, 3.2, etc. (I'm not typing sixty-bit digit streams!) where in computer terms, these are the exact machine numbers and values between them are not representable. Thus, pi would be 3.1, the nearest machine number. The function values F(3.0), F(3.1), etc. are to be tabulated, and obviously, they shoud be machine values correctly rounded at the lowest digit. The difficulty question is: how much additional precision is needed to calculate these results so as to guarantee that the results are correctly rounded? There is no general answer. But of the common functions, exp(x) does have very large slopes, so a decision for that will likely be good for other functions. Then again, sqrt(x) is very steep near zero. I don't have any "horrible examples" to hand, but the principle is clear. Thus, using double precision to calculate a function of a single-precision argument will give results that rounded to single precision will be proper. Probably. Not certainly at all. Every function will require its own analysis for confidence to have a proper basis. And the nub of the problem is this: suppose F(x) evaluates as 6.45, which is to be rounded to one decimal digit. Is the value really 6.450000... or, 6.4499999...? NickyMcLean (talk) 03:13, 23 February 2012 (UTC)
- I have trouble with the thesis that there was one problem that drove the choice of 64 bits. If that problem showed 67 bits were needed, then would 67 bits have been used? (Another level on the barrel shifter?) What about even simpler functions that have worse behavior? If I take the sqrt(x), then the result has about half the precision of the argument. The cost/benefit seems a better focus.
- I recall seeing a paper in the 80s (I think by Kahan; maybe others; maybe it was argument on the draft standard; possibly Computer Magazine) that discussed the features of IEEE 754. One concern was protecting the naive programmer who didn't pay attention to the dynamic range of the intermediate results. (See IEEE 754-1985 desideratum 2, enhance capability and safety for non expert programmers.) He might multiply 6 large numbers together, and then divide by another product of 6 numbers. The answer might be close to one, but the intermediate values could overflow a basic format. The exponent issue was sensitive for single float numbers because many physical values were close to the basic limit. (Maybe there was more in the paper; some early FP units might get the right because they computed a modular exponent; IEEE-754 would complain to protect the programmer from believing a bad result; extra headroom could keep old code running.)
- I don't recall reasons for a larger precision, but matrix operations provide a huge opportunity for losing precision. Non-expert programmers are also an issue. Using the simple formula for sinh(x) near 0 begs for substantial cancellation.
- I believe there are many reasons for the choice of an 80-bit extended format. I don't have trouble with a sourced explanation showing that 80 bits is reasonable for log/exp, but I don't think the sources suggest that log/exp is the reason for 80 bits.
- My sense is extended precision was supposed to work behind the scenes, but application programmers wanted and were given access to it.
- Glrx (talk) 02:25, 2 March 2012 (UTC)
- I agree with this-- extended precision is part of a larger design aim to improve the robustness of all numerical codes and exponentiation is one, perhaps pivotal, example of this. I have added "A notable example of.." to this section to indicate that it is one consideration amongst many, and added a further reference by Kahan describing the limitation to a maximum of 64 bits significance due to speed issues. Brianbjparker (talk) 01:25, 10 March 2012 (UTC)
- I'm sure there were many reasons for wanting as much precision. It is clear that Prof. Kahan would take as many bits as he could possibly get. But in an era where they needed to keep designs as compact as possible, they apparently needed some sort of "smoking gun" reason to justify more bits. I have now read two books written by the designers of the 8087 and 80287 and it appears that exponentiation was that reason. One of the goals was to have 1/2 ULP (Units in the Last Place) precision for all elementary operations. If they had wanted, they could accomplish this with just 64-bit formats for all elementary math (add, subtract, multiply, etc), trig, log, and 2x functions. Many of the HP Journals have descriptions on how this can be done. If they had chosen to implement exponentiation via repeated multiplication, they probably could have done exponentiation with just 64 bits as well. However they chose to use the 2Y × Log2 X algorithm. To provide 1/2 ULP accuracy for 64-bit exponentiation, they needed an 80-bit intermediate value. I suppose they could have taken the cheap way out (as Pascal did) and decide that exponentiation was not an elementary operation but they decided to do things right.
- Matrix math was probably not all that compelling a reason at the time because matrixes were relatively small and relatively rare. In addition, the rounding features built in to the 8087 were designed to minimize accumulated rounding error over large numbers of iterations. However every math student, chemist, and loan officer was performing polynomial evaluation and exponentiation every day so exponentiation had to be done right.
- Note that Prof. Kahan did not win all his battles. When he first joined the 8087 project, he apparently wanted the 8087 to do math in decimal but the design was too far along to change so we are stuck with binary math in the 8087 and all the problems that come along with that design.
- --Bill 14:33, 13 March 2012 (UTC)
Number of significant digits in the 80-bit format
[edit]Given that there are 64 bits of precision, the extended precision format can only represent 19 decimal digits of precision. The Integer(Log10 2Number of bits) formula is a time-honored formula for computing the number of decimal digits a given number of bits can store. For example, assume a 4-bit value. The representable values are 0, 1, 2, ... 14, 15. This 4-bit value can only one one decimal digit of precision because many two decimal-digit values (16, 17, ..., 98, 99) cannot be represented. Note that Log10 24 = 1.2041. 7 bits are needed to hold a 2 decimal digit value: Log10 27 = 2.1072.
I think that Prof. Kahan's paper is being taken a little out of context here. His paper mentions that the Extended format supports ≥18-21 significant digits. This is true because an IEEE-754 double-extended value has 64 or more bits of precision. The x86 Extended Precision value has exactly 64 bits of precision so it only supports 19 decimal digits.
Prof. Kahan's statement that Extended supports ≥18 decimal digits is true because 19 is greater than 18. He may have mentioned 18 digits because the x86 contains an instruction that will convert an extended precision value to 18 BCD digits.
The following statement should probably be removed from the article: "(if a decimal string with at most 18 significant decimal is converted to 80-bit IEEE 754 double extended precision and then converted back to the same number of significant decimal, then the final string should match the original; and if an IEEE 754 (80-bit) double extended precision is converted to a decimal string with at least 21 significant decimal and then converted back to double extended, then the final number should match the original."
The clause "...(if a decimal string with at most 18 significant decimal is converted to 80-bit IEEE 754 double extended precision and then converted back to the same number of significant decimal, then the final string should match the original;..." really talks about the quality of a piece of software that can perform such a conversion, not about the extended precision format itself.
The clause "...and if an IEEE 754 (80-bit) double extended precision is converted to a decimal string with at least 21 significant decimal and then converted back to double extended, then the final number should match the original" is misleading because the converse is not true. It is true that an 80-bit value can be converted to a 21-decimal digit value and then converted back to the original 80-bit value. The converted value will have several leading zeros. It is false that every 21-digit decimal value can be converted to an 80-bit binary value and then converted back to the original 21-digit decimal value. A 21-decimal digit value requires at least 70 bits of precision and the 80-bit format only has 64 bits. --Bill 14:35, 13 March 2012 (UTC)
- No, this text is correct and it does explicitly refer to the 80-bit format. The number of decimal digits associated with a binary representation cannot really be represented by a single number. There are two well-defined values for the number of decimal digits (for correct-rounding) depending on what the use is: for an 80-bit extended precision , if you have a decimal string with 18 significant decimals and you convert it to 80-bit binary IEEE 754 precision and then convert it back to decimal representation (all correctly rounded) then the final string will be exactly the same; and if you do the round trip in the other direction (binary to decimal to binary) you will find that as long as you save at least 21 digits of precision for the decimal (and many trailing digits will often be zero) then you will be able to convert it back and get exactly the same binary value.
- So the text is correct, but that may not be clear and maybe should be rewritten. I think it is worth having this information here as it is practically necessary (and while those upper and lower limits can be found as constants in e.g. C headers (math.h) it is good to have them easily available here). (note that these limits are not a quality-of-implementation issue-- they are provable mathematical properties of the format.) Brianbjparker (talk) 09:18, 16 March 2012 (UTC)
- The statement about 18 to 21 digits of precision is misleading given that there are only 19.2 digits of information in 64 bits. The article does point out the log formula. It then explains the origin of the numbers 18 and 21. I agree with Brian that (1) the statements are not claiming the converse is true and (2) the writing could be improved. Glrx (talk) 22:35, 17 March 2012 (UTC)
- It figures that things are more complicated than you would think. I've done a lot of experimenting and agree with the 18-digits minimum significant digits. One thing I've noticed is that since bit 63 is always 1, there are really only 263 different representable significands. Thus I understand and agree with the floor((N-1)Log10(2)) calculation (which is the same as the floor(Log10(2(N-1))) calculation referenced in the original article except that the exponent is 63 rather than 64).
- The "at most" calculation is probably misleading. As an experiment, see the attached table of values for an IEEE 754 for 4- and 5-bit precision. According to the formulas, both the 4-bit and 5-bit formats would provide up to 3 digits of accuracy. For example, the 5-bit value 20 x 1.00012 is decimal 1.062510 exactly. If this were rounded to two digits (i.e. 1.110) it would convert back to binary 20 x 1.00102. However the casual reader might read the "3 digits maximum" and might think that (for instance) 1.0510 and 1.0610 would have different binary representations.
- But those results don't contradict the definition, right? If the decimal 1.0625 is rounded to *3* decimal digits to give 1.06 that will convert back to the original 1.0001 binary value. If there would be problem of a casual reader misinterpreting the definition as given, perhaps a clearer wording could be found. Brianbjparker (talk) 04:58, 23 March 2012 (UTC)
- The "at most" calculation is probably misleading. As an experiment, see the attached table of values for an IEEE 754 for 4- and 5-bit precision. According to the formulas, both the 4-bit and 5-bit formats would provide up to 3 digits of accuracy. For example, the 5-bit value 20 x 1.00012 is decimal 1.062510 exactly. If this were rounded to two digits (i.e. 1.110) it would convert back to binary 20 x 1.00102. However the casual reader might read the "3 digits maximum" and might think that (for instance) 1.0510 and 1.0610 would have different binary representations.
- It strikes me that the Decimal->Binary->Decimal conversion is what most people will think of when talking about digits of precision. People enter numbers into computers in decimal and expect to get answers back in decimal. Once inside a computer, a number tends to stay in binary. Therefore we should simply say 18 significant digits.
- --Bill 16:01, 20 March 2012 (UTC)
| Exponents = 0 or 1 | Exponents = 2 or 3 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 4-Bit Precision | 5-Bit Precision | 4-Bit Precision | 5-Bit Precision | ||||||||
| Binary | Decimal | Binary | Decimal | Binary | Decimal | Binary | Decimal | ||||
| 20 x 1.000 | 1 | 20 x 1.0000 | 1 | 22 x 1.000 | 4 | 22 x 1.0000 | 4 | ||||
| 20 x 1.0001 | 1.0625 | 22 x 1.0001 | 4.25 | ||||||||
| 20 x 1.001 | 1.125 | 20 x 1.0010 | 1.125 | 22 x 1.001 | 4.5 | 22 x 1.0010 | 4.5 | ||||
| 20 x 1.0011 | 1.1875 | 22 x 1.0011 | 4.75 | ||||||||
| 20 x 1.010 | 1.25 | 20 x 1.0100 | 1.25 | 22 x 1.010 | 5 | 22 x 1.0100 | 5 | ||||
| 20 x 1.0101 | 1.3125 | 22 x 1.0101 | 5.25 | ||||||||
| 20 x 1.011 | 1.375 | 20 x 1.0110 | 1.375 | 22 x 1.011 | 5.5 | 22 x 1.0110 | 5.5 | ||||
| 20 x 1.0111 | 1.4375 | 22 x 1.0111 | 5.75 | ||||||||
| 20 x 1.100 | 1.5 | 20 x 1.1000 | 1.5 | 22 x 1.100 | 6 | 22 x 1.1000 | 6 | ||||
| 20 x 1.1001 | 1.5625 | 22 x 1.1001 | 6.25 | ||||||||
| 20 x 1.101 | 1.625 | 20 x 1.1010 | 1.625 | 22 x 1.101 | 6.5 | 22 x 1.1010 | 6.5 | ||||
| 20 x 1.1011 | 1.6875 | 22 x 1.1011 | 6.75 | ||||||||
| 20 x 1.110 | 1.75 | 20 x 1.1100 | 1.75 | 22 x 1.110 | 7 | 22 x 1.1100 | 7 | ||||
| 20 x 1.1101 | 1.8125 | 22 x 1.1101 | 7.25 | ||||||||
| 20 x 1.111 | 1.875 | 20 x 1.1110 | 1.875 | 22 x 1.111 | 7.5 | 22 x 1.1110 | 7.5 | ||||
| 20 x 1.1111 | 1.9375 | 22 x 1.1111 | 7.75 | ||||||||
| 21 x 1.000 | 2 | 21 x 1.0000 | 2 | 23 x 1.000 | 8 | 23 x 1.0000 | 8 | ||||
| 21 x 1.0001 | 2.125 | 23 x 1.0001 | 8.5 | ||||||||
| 21 x 1.001 | 2.25 | 21 x 1.0010 | 2.25 | 23 x 1.001 | 9 | 23 x 1.0010 | 9 | ||||
| 21 x 1.0011 | 2.375 | 23 x 1.0011 | 9.5 | ||||||||
| 21 x 1.010 | 2.5 | 21 x 1.0100 | 2.5 | 23 x 1.010 | 10 | 23 x 1.0100 | 10 | ||||
| 21 x 1.0101 | 2.625 | 23 x 1.0101 | 10.5 | ||||||||
| 21 x 1.011 | 2.75 | 21 x 1.0110 | 2.75 | 23 x 1.011 | 11 | 23 x 1.0110 | 11 | ||||
| 21 x 1.0111 | 2.875 | 23 x 1.0111 | 11.5 | ||||||||
| 21 x 1.100 | 3 | 21 x 1.1000 | 3 | 23 x 1.100 | 12 | 23 x 1.1000 | 12 | ||||
| 21 x 1.1001 | 3.125 | 23 x 1.1001 | 12.5 | ||||||||
| 21 x 1.101 | 3.25 | 21 x 1.1010 | 3.25 | 23 x 1.101 | 13 | 23 x 1.1010 | 13 | ||||
| 21 x 1.1011 | 3.375 | 23 x 1.1011 | 13.5 | ||||||||
| 21 x 1.110 | 3.5 | 21 x 1.1100 | 3.5 | 23 x 1.110 | 14 | 23 x 1.1100 | 14 | ||||
| 21 x 1.1101 | 3.625 | 23 x 1.1101 | 14.5 | ||||||||
| 21 x 1.111 | 3.75 | 21 x 1.1110 | 3.75 | 23 x 1.111 | 15 | 23 x 1.1110 | 15 | ||||
| 21 x 1.1111 | 3.875 | 23 x 1.1111 | 15.5 | ||||||||
- Interesting experiments. You are probably right when you say that the Decimal->Binary->Decimal conversion use case is the most common. However, I think both limits 18 (floor((p-1)log_10(2))) and 21 (ceil(1+p log_10(2))) should be listed on the article because: both values together fully characterize all meanings of equivalent decimal digits for a binary floating point format; there are use cases where the upper limit is needed, for example the C float.h header gives both (LDBL_DECIMAL_DIG and LDBL_DIG); and for consistency with the other formats in wikipedia (float and double) which list both. Brianbjparker (talk) 04:43, 23 March 2012 (UTC)
Please excuse me for going out on a limb questioning a fancy formula by a famous person but... Wikipedia is governed by the laws of the state of Florida so I have a constitutional right to make a fool out of myself! So here I go...
In summary: I think the number of significant digits is 19 and that we should not state that you will get up to 21 significant digits because this number will be misinterpreted by most readers. What follows is my reasoning.
This article will be mainly read by casual public rather than by skilled numerical analysts so it should really be targetted towards them. The term significant digits has a specific meaing to the general public which translates to ½ ULP accuracy (see the Wikipedia article). For example, if I measured a golf ball's diameter and said that it is 1.68 inches in diameter, you would expect that I have specified three significant digits and that if the golf ball were measured with infinite accuracy, the true diameter would be somewhere between 1.675 and 1.684999999 inches. A numeric analyst or scientist would prefer to give a more specific indication of uncertainty such as 1.68±0.005 inches.
I think that if the casual person is asking about decimal conversion of a binary value, they are really trying to "measure" the value in decimal. In other words, if the variable "x" is converted to decimal, what is the maximum number of decimal places that can be shown such that the true value of "x" is still within ½ ULP.
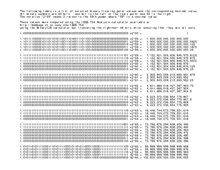
Here is one one way of translating that expectation to a real number. The first thing to recognize is that every integer from 0 through 264 can be represented exactly using the extended precision format. The attached picture illustrates the larger values.
264 is approximately 1.8×1019 which is a 20-digit number. Since some 20-digit integers can be represented, all 19-digit integers can be represented. Thus this format is capable of supporting 19 significant digits for integers. Since significant digits is unaffected by scale, this format would support 19 significant digits at all scales, not just for integers.
In summary, if a binary value "x" was converted to 19 decimal digits, the end user would be sure that the true value of "x" would be within ½ of a digit of the 19th digit.
| Binary Values | Range of Integers |
|---|---|
| 1.xxxx × 263 | 9.2×1019 thru 18.4×1019 |
| 1.xxxx × 262 | 4.6×1019 thru 9.2×1019 |
| 1.xxxx × 261 | 2.3×1019 thru 4.6×1019 |
| 1.xxxx × 260 | 1.15×1019 thru 2.3×1019 |
| 1.xxxx × 259 | 1×1019 thru 1.15×1019 |
So the next question is: what is wrong with the formula: floor((N-1) Log10(2))? This works great for integers and fixed point numbers but it ignores the effect that the variable exponent has on the range of representable numbers. Since the most significant bit of the characteristic is 1, only a certain range of integers can be represented for a given exponent of two. To cover all integers, it is necessary to use several values for the exponent of 2 as illustrated by the table at the right. I think I have located a citeable reference but unfortunately it is located at a university library which is about 30 miles away so it will be a while before I can get to it.
As for the other formula "ceil(1 + N Log10(2))" regarding the maximum significant digits: While I understand where it comes from, I cannot think of a comprehensible way of explaining it to the average reader. They might think that for certain values, they would get lucky and see 21 significant digits. In actuality, as shown by the attached table, you really only get 20 significant digits for values where the first six digits are less than approximately 184467. --Bill 02:56, 26 March 2012 (UTC)
If you want to get into the details of significant digits in binary values, then you should also look into the significance in decimal values. While it is common to say "3 significant digits" for any value given to three places, it isn't quite right. Note that 100 (or 10.0 or 1.00) have only two significant digits, while 999, 99.9 and 9.99 have about 2.999 or almost three. That is, the relative uncertainty for 1.00 is one part in 100, while for 9.99 it is one part in (almost) 1000. The number of significant digits, then, is just log base 10 of the significand, and so the number of significant bits is log base 2 of the significand. Following that, the 64 bit significand for x87 format allows for between 63 and 64 significant bits, or between 18.96 and 19.26 decimal digits. Gah4 (talk) 06:41, 18 December 2012 (UTC)
Meaning of "reviving the acccuracy"
[edit]The phrase starting "also reviving the issue of the accuracy of functions of such numbers, but at a higher precision" isn't clear to me. I am not saying it is wrong, just that the meaning isn't clear. Do you mean that because there is now an 80-bit long double available in C, for example, that the question arises of how to compute library functions returning *this* 80-bit precision without using an even higher precision format in its implementation? Given the intended role of 80-bit extended as support for internal computations for a final double precision result, in practice that wouldn't be a major issue, would it? But it is true that library functions returning long double are provided, I am not sure if they provide full 64-bit precision. Brianbjparker (talk) 01:43, 24 March 2012 (UTC)
- Previously, there had not been much explanation of the motive for the 80-bit format being 80, other than an initial suggestion that the hardware would have a 64-bit integer operation just as it offers 64-bit floating-point, and "with trivial additional circuitry" there could therefore be an extended precision floating-point format with a 64-bit mantissa, just as with the IBM1130 in fact having 32-bit integer arithmetic so that a 32-bit precision floating-point format was easy. To store the exponent for the 64-bit mantissa, another 16-bit word (them were days of 16-bit word pcs) means 80 bits, and voila! Then came discussion of how to compute exp(x) in particular, accurate to double precision's last bit, a 64-bit internal computation was helpful. Plus a quote from Prof. Kahan that 64-bit precision arithmetic was the widest that could be achieved without additional slowing of the hardware. All well and good. But because a task may be interrupted at any time, it is necessary that all involved registers have their state saved so that on resumption of the task its calculation can resume. Thus, there arose arrangements to save and restore 80-bit registers. (Despite years of ineffectual wonderings, I still have seen no clear statement about the special bits associated with those registers, concerning the state of special guard bits beyond the 80 [And on re-reading yet again my manual for the 8087 this time I see that the additional guard bits are disregarded between operations - that is, they are used only during an operation to help in the rounding of the final result and their state at the end of an operation is ignored when a new operation begins so there is no need to save it on interrupt]) This of course means that 80-bit floating point numbers are now available for computation.
- Persons concerned no further than double precision need pay no attention to this, and their double precision function evaluations will be evaluated as is desired, and the existence of REAL*10 possibilities will indeed not be a major issue for them as such. But others, intending calculation with REAL*10, will be wondering about the precision of exp(x)'s evaluation. Possibly, a different evaluation method will be used, but, to follow the (realtively easier and faster) REAL*8 method of employing a much higher precision will in turn require a still higher precision than REAL*10, reviving the issue as remarked. And if it were to involve a REAL*12 (say) format, then the registers must be saveable, and another iteration begins. NickyMcLean (talk) 03:01, 24 March 2012 (UTC)
- Thanks for clarifying. I think a problem with the article focussing too much on the historical reasons for choosing 80 bits in particular is that it obscures the higher level design aims for use of extended precision as clearly articulated in Kahan's published works: that users' intermediate calculations need to carry additional precision to minimise roundoff in the final result, for all calculations, as has been the historical practice in scientific calculation whether by hand or calculator (not just library implementations). Kahan and co-architects wanted as much additional precision in the extended format as possible. As he says: "For now the 10-byte Extended format is a tolerable compromise between the value of extra-precise arithmetic and the price of implementing it to run fast; very soon two more bytes of precision will become tolerable, and ultimately a 16-byte format... That kind of gradual evolution towards wider precision was already in view when IEEE Standard 754 for Floating-Point Arithmetic was framed.". I fear that speculating too much in the article on the engineering reasons it was limited to 80-bit in x87 makes extended precision itself sound like an implementation artifact that was only made available to users as an historical accident, rather than a key feature that should be used routinely. As your point about REAL*12 libraries indicates, numerical experts don't absolutely require extended precision to implement the standard math functions, so speculation that that was the key reason is probably incorrect-- we should focus on the published reasons of the x87 designer. However, I think that the phrase "also reviving the issue of the accuracy of functions of such numbers, but at a higher precision" is not ideal for an encyclopaedic article and would be better removed, as it is too obscure (and philosophical) to be helpful for most readers. Just my 2 cents worth.
- Brianbjparker (talk) 09:32, 25 March 2012 (UTC)
- Having suffered endlessly from manuals, etc. that turn out to be vague on details, I favour encyclopaedic coverage of details, and given all the fuss now presented over the reason for REAL*10 evalualtion to ease the assurance of correctness for REAL*8 results (and REAL*4), I feel also amusement that the solution of the problem itself revives the same issue but at a higher level. I think there should be some note of the question of the accuracy of REAL*10. NickyMcLean (talk) 21:09, 25 March 2012 (UTC)
- Fair enough. Another major reason double extended needs to be saved to memory and accessible in programming languages is to save temporary results for the case of a floating point calculation extending over multiple statements, so the internal computations are performed in extended precision for the entire function (I have added some words to that effect in the sentence). Brianbjparker (talk) 22:00, 25 March 2012 (UTC)
- Comments on x87 FP stack: http://www.cims.nyu.edu/~dbindel/class/cs279/stack87.pdf Glrx (talk) 22:17, 25 March 2012 (UTC)
- That is an interesting paper-- although the x87 stack architecture is widely criticised, it really seems to have some potential advantages if done properly. I have actually previously added that reference to the x87 article, where it is a better fit as there was already a discussion of the x87 stack architecture. Brianbjparker (talk) 03:52, 26 March 2012 (UTC)
- Comments on x87 FP stack: http://www.cims.nyu.edu/~dbindel/class/cs279/stack87.pdf Glrx (talk) 22:17, 25 March 2012 (UTC)
- Just as background -- much of my information comes from the Palmer/Morse books. I suspect that the ability to store the internal format in memory was driven by more than just the need to save state during interrupts. As Glrx has noted, the 8087 stack implementation was a mess. Palmer dedicated a chapter in his book on how to program the 8087 as a register machine and he was the guy that was in charge of designing the chip. He almost apologizes for the design in his book. This kind of design requires the ability to store intermetiate results to memory.
- Regarding the 64-bit significand and the evolution of designs: The single-, double-, and extended-precision formats were designed together and implemented in the 8087. I think the 64-bit adder (actually a 66- or 67-bit adder) mentioned in the previous version of the article was actually driven by the need to support the extended precision format rather than the need to support 64-bit integers. The chip was really designed to handle the single- and double-precision formats. To do that right, they needed a 64-bit adder. Support for 64-bit integers was probably added because it was easy to do.
- Regarding the emphasis on exponentiation: It is surprizing what a difficult operation that really is. You can lose more precision in a single exponentiation operation than you would in a thousand multiplies or adds. Would you buy a 10-digit calculator that said ((10^40)^2) = 9.999999600×1079? Even though the HP-35 internally worked in decimal and did internal calculations to 11 digits, it still lost unacceptable precision when exponentiating large numbers. Prof. Kahan was deeply involved in the design of this calculator and probably became painfully aware of this problem. I'll add a little more color on this tomorrow.
- --Bill 04:06, 26 March 2012 (UTC) — Preceding unsigned comment added by BillF4 (talk • contribs)
- As an experiment to demonstrate the precision loss that occurs through exponentiation, see the following program that calculates 310185 using both exponentiation and repeated multiplication. 310185 is actually 3(3×5×7×97) so the other values in the list are rearrangements of these exponents. For example 2187 is 37 while 1455 is 3×5×97. The program is written in Turbo Pascal 5.5 which can be downloaded for free from embarcadero: http://edn.embarcadero.com/article/20803
- The following results are reported to 18 significant digits which is the maximum that Turbo Pascal will generate. Notice that only the first 15 digits are the same across all calculations. When repeated multiplication is used, the values are the same except for 21871455 where the last digit is different by one. Note that 310185 involved 10184 multiplications while the 21871455 1454 multiplications. In all cases, there was only a single exponentiation operation.
3 0198079197408727519345225195767135427384 (arbitrary precision) 3.01980791974087235E+4859 = 3 ^ 10185 (exponentiation) 3.01980791974087274E+4859 = 3 ^ 10185 (multiplication) 3.01980791974087421E+4859 = 2187 ^ 1455 (exponentiation) 3.01980791974087276E+4859 = 2187 ^ 1455 (multiplication) 3.01980791974087421E+4859 = 14348907 ^ 679 (exponentiation) 3.01980791974087275E+4859 = 14348907 ^ 679 (multiplication) 3.01980791974087235E+4859 = 10460353203 ^ 485 (exponentiation) 3.01980791974087275E+4859 = 10460353203 ^ 485 (multiplication) 3.01980791974087421E+4859 = 50031545098999707 ^ 291 (exponentiation) 3.01980791974087275E+4859 = 50031545098999707 ^ 291 (multiplication)
{$N+,E-}
var x1, r, ln2: extended;
var s: string;
var x2, x3, i : longint;
function XtoYBase2(var x:extended; var y:extended):extended;
begin
XtoYBase2 := exp(ln2 * (y * (ln(x) / ln2)));
end;
procedure ShowPower(var x:extended; var sx:string; var y:longint);
var v1, v2 : extended;
begin
v1 := x;
v2 := y;
r := XtoYBase2(x, v2);
writeln(r:27:20, ' = ', sx, ' ^ ', y, ' (exponentiation)');
v2 := 1;
for i := 1 to y do
v2 := v2 * v1;
writeln(v2:27:20, ' = ', sx, ' ^ ', y, ' (multiplication)');
writeln;
end;
begin
ln2:=ln(2);
x1 := 3; x2 := 10185;
s := '3';
ShowPower(x1, s, x2);
x1 := 2187; x2 := 1455;
s := '2187';
ShowPower(x1, s, x2);
x1 := 14348907.0; x2 := 679;
s := '14348907';
showpower(x1, s, x2);
x1 := 10460353203.0; x2 := 485;
s := '10460353203';
showpower(x1, s, x2);
x1 := 50031545098999707.0; x2 := 291;
s := '50031545098999707';
showpower(x1, s, x2);
end.
- In contrast to exponentiation, almost all other basic functions (i.e. those you would find on any scientific calculator such trig and log) can be computed with just a few extra bits using either cordic or well-crafted polynomial approximation.
- --Bill (talk) 16:22, 27 March 2012 (UTC)
Lopsidedness.
[edit]The intel 80-bit format is very common even if messy because not as similar to the 64-bit and 32-bit schemes as it could be (abandonment of the implicit-one bit, and I think there are differences in rounding or something), so I suppose it is reasonable to have the example based on it. But if only the intel form is considered, this article might as well be subsumed into the discussion of the intel 8087 format, the IEEE standards, and regulatory capture (that the historic accident became "standardised"). However, the other uses of extended precision did exist, and even though I don't offhand know of any current computer using them, an encyclopaedic article should at least mention them. It seems to me that "extended" precision refers only to the usage outside the common doubling and redoubling of word sizes, even if (as with the B6700) the word size is not itself a power of two. NickyMcLean (talk) 20:36, 19 December 2010 (UTC)
- The reason for the 80-bit extended format is (1) IEEE FP requires extended precision for intermediate results and (2) a processor must be able to save the state of its FP unit -- including its registers / intermediate values. Language designers / compiler writers, for whatever reasons, gave the programmer access to the internal representation. The implicit bit and denormalized numbers are bit packing / encoding issues. There is no reason that an FPU's internal hardware have or use (awkward) representations for the implicit bit or denormalized numbers. Glrx (talk) 04:25, 20 December 2010 (UTC)
and/or
[edit]Extended precision refers to floating point number formats that provide greater precision and more exponent range
Seems to me that in some cases the exponent range is not increased. (Consider the IBM S/370 extended precision (IBM term) format.) Can we change this to and/or? [1] Gah4 (talk) 23:20, 5 May 2015 (UTC)
References
real*10
[edit]Is it possible to say explicitly that this is the real*10 of gfortran (or to say that is not)? By the way, the presence of real*10 in the text would make far easier to arrive here.
Someone might be interested in the output of this program C1234x
CHARACTER*80 C80
CHARACTER*16 C16
CHARACTER*10 C10
CHARACTER*8 C08
CHARACTER*4 C04
INTEGER*4 I04(20),J04
INTEGER*8 I08(10),J08
REAL*4 R04(20),S04
REAL*8 R08(10),S08
REAL*10 R10( 5),S10
REAL*16 R16( 5),S16
EQUIVALENCE (C80,R16,R10,R08,R04,I08,I04)
EQUIVALENCE (C16,S16),(C10,S10),(C08,S08,J08),(C04,S04,J04)
C
DO K=1,80
C80(K:K)=CHAR(32+K)
ENDDO
WRITE (6,'(2A)') C80,' datum'
C
DO K=1,5
S16=R16(K)
WRITE (6,'(A,$)') C16
ENDDO
WRITE (6,'(A)') ' real*16'
C
DO K=1,5
S10=R10(K)
WRITE (6,'(A," ",$)') C10 ! note the 6 blanks
ENDDO
WRITE (6,'(A)') ' real*10'
C
DO K=1,10
S08=R08(K)
WRITE (6,'(A,$)') C08
ENDDO
WRITE (6,'(A)') ' real*08'
C
DO K=1,20
S04=R04(K)
WRITE (6,'(A,$)') C04
ENDDO
WRITE (6,'(A)') ' real*04'
C
DO K=1,10
J08=I08(K)
WRITE (6,'(A,$)') C08
ENDDO
WRITE (6,'(A)') ' int*08'
C
DO K=1,20
J04=I04(K)
WRITE (6,'(A,$)') C04
ENDDO
WRITE (6,'(A)') ' int*04'
STOP
END
that is
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnop datum !"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnop real*16 !"#$%&'()* 123456789: ABCDEFGHIJ QRSTUVWXYZ abcdefghij real*10 !"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnop real*08 !"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnop real*04 !"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnop int*08 !"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnop int*04
because gives info on the memory allocation. I have worked on x86, UBUNTU-20, gfortran-9.3.0. NOTE: I first suspected something strange when I noticed that the unformatted dumps in real*16 and real*10 had the same lengths. 151.29.83.146 (talk) 13:56, 25 September 2021 (UTC)
- B-Class Computing articles
- Mid-importance Computing articles
- B-Class software articles
- Low-importance software articles
- B-Class software articles of Low-importance
- All Software articles
- B-Class Computer hardware articles
- Low-importance Computer hardware articles
- B-Class Computer hardware articles of Low-importance
- All Computing articles