
File:IBM CJK Code Page Numbers.svg

Size of this PNG preview of this SVG file: 800 × 525 pixels. Other resolutions: 320 × 210 pixels | 640 × 420 pixels | 1,024 × 672 pixels | 1,280 × 840 pixels | 2,560 × 1,681 pixels | 1,086 × 713 pixels.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Original file (SVG file, nominally 1,086 × 713 pixels, file size: 10 KB)
| This is a file from the Wikimedia Commons. Information from its description page there is shown below. Commons is a freely licensed media file repository. You can help. |
{kind=link}
Summary
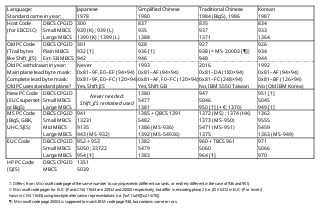
| Description | Overview of IBM CJK DBCS CPGIDs and MBCS CCSIDs. Although there existed variable-width Host Code and Old PC Code for Thai also, that is not CJK and I'm not aware of any available documentation for them, so they are not shown. |
| Date | |
| Source | Own work (see commentary below) |
| Author | User:HarJIT |
| Permission (Reusing this file) |
I, the copyright holder of this work, hereby publish it under the following license: This file is licensed under the Creative Commons Attribution 4.0 International license.
|
Details
Some points of elaboration, in order of appearance in the table:
- 300 (930, 939, 1390, 1399): The preferred layout for single-byte mode (shift-in mode) katakana in EBCDIC collides with the preferred/invariant layout for Basic Latin lowercase. CCSIDs 930 and 1390 use the preferred layout for kana and dislocate the lowercase (in one of at least three entirely mutually incompatible schemes that exist for dislocating the lowercase). CCSIDs 939 and 1399 use the preferred layout for lowercase and dislocate the kana (in one of at least two schemes that exist for doing that, which are only compatible with each other for wo, small kana and A through Tsu, colliding thereafter). Specifically, CCSIDs 930 and 1390 use CPGID 290 (not 1136) as their SBCS, and CCSIDs 939 and 1399 use CPGID 1027 (not 298) as their SBCS. CPGID 300 is a Japanese double-byte EBCDIC which doesn't base its layout on any edition of JIS X 0208 (its first revision probably predates it), as opposed to the at-least two rival Japanese double-byte EBCDICs which do. For more on the absolute gore which is EBCDIC in Japan, see Japanese language in EBCDIC. Finally, the CCSID 16684 (which refers to the expanded version of CPGID 300, as included in CCSIDs 1390 and 1399 as opposed to 930 and 939) has its own codec in ICU (i.e. without either shift-in mode), uniquely amongst the EBCDIC DBCSes.
- 301 (932, 942): Unlike CPGID 941, this undoes the codepoint swaps made in the 1983 edition of JIS X 0208, and excludes two of the additions made by said 1983 edition that duplicated existing IBM extensions. It also does not include any NEC extensions.
- 928 (936, 946): Not related to Windows-936. Part of the series of four encodings ("PC Data" in the original IBM 5550 sense) defined using Shift JIS's trail byte system, including Shift JIS itself. Was last defined in the 1992-11 edition of C-H 3-3220-130, as opposed to the 1993-11 edition which is the only one publicly available, but no longer defines CPGID 928 (although it still lists lead byte ranges for it when constrained to particular GCSGIDs, e.g. level 1 hanzi). The ICU project has a mapping, but doesn't include it in the main repo or ship it with the product. Mark Leisher's
SHIFTGB.TXTis a subset. - 927 (938, 948): Part of the same series of encodings as CPGID 928, and easily the second-best documented of them (after, of course, Shift JIS), since it is included in the publicly available 1999-04 edition of C-H 3-3220-126 (CPGID 947 for Big5 was instead defined in a separate document, C-H 3-3220-131 1999-04). Actually roughly matches a subset of Shift JIS for the first few lead bytes, although this is followed by a section of further non-hanzi and then the two hanzi sections. It was not dropped until the 2016-04 edition of C-H 3-3220-126, which expanded CPGID 835 but discontinued CPGID 927, removing the CPGID 927 charts, and replacing the CPGID 927 mappings in the CPGID 835 charts with CPGID 947 mappings. Microsoft attempted to implement this as Code page 20003 but, ignoring omissions (of duplicates or presumed later additions) and the usual minor mapping disagreements, it also has several clear errors:
- Microsoft map 0x814C to U+2035 (grave accent) and 0x814D to U+2032 (acute accent), instead of vice versa.
- Microsoft map 0x8157 to U+3004. Although this character is one of two separate encodings of U+4EDD in this code page (IBM maps this one to U+F83E, a private use code point defined in CPGID 1449, for round trip purposes), mapping to U+3004 is a mistake based on Unicode 1.0.0, when 仝 was at U+3004 (not U+4EDD) and 〄 was at U+32FF (not U+3004).
- Most significantly, Microsoft pivot 0xA9C2 through 0xA9CB (ten level 2 hanzi) so that 0xA9C2 (properly U+6265) has the mapping of 0xA9C3 (U+625C) and so forth, with 0xA9C2's mapping (U+6265) looping around to be used for 0xA9CB (properly U+625A).
- 926 (934, 944): Part of the same series of encodings as CPGIDs 927 and 928, this was last defined in the 1989-10 edition of C-H 3-3220-125. Similarly, the only publicly available edition is the 1992-09 edition. The lead bytes indicate (correctly) a plane laid out very differently from the KS X 1001 one, and it would not have been possible to reconstruct it given that document alone. Thankfully, an IBM-supplied CCSID 944 mapping was included in very early versions of ICU (although it's now been relegated to the ICU-data repository and is no longer shipped with the ICU software). The plane, while indeed very different from the KS X 1001 one, shows textual dependence in both directions: it has very clearly been expanded to make its repertoire a superset of the KS X 1001 one (this is clearly visible for the syllables and exceptionally visible for the hanja, but in places discernable for the specials as well), but the KS X 1001 one seems itself to have loosely based its first row on an earlier version of the IBM-944 first row, occasionally with glyph changes which IBM evidently didn't see fit to unify back when adding the KS X 1001 repertoire; the combined effect of these causes an interesting doublet effect in parts of row 1, notably the inequality symbols. This dependence might be indirect via CPGID 834, which shows evidence of being either based on CPGID 926 or developed in tandem with it, and might have been included in an appendix in the second edition of KS C 5601; however, it is not possible to reconstruct the syllable encoding (i.e. the most important part of a Korean character set) for CPGID 926 purely with reference to other code pages, since CPGID 834 uses Johab layout for syllables and, while CCSID 933 constrains the repertoire to that of CCSID 944, it is not possible to determine from that which syllables are in the original range versus which are in the KS X 1001 supplement range (one would be able to distinguish some which must be in the former due to being absent in KS X 1001, but unable to distinguish those which are in both KS X 1001 and the original range from those in the KS X 1001 supplement range), so the demoted ICU mappings are the sole publicly available source for the syllable portion of CPGID 926 that I know of.
- 1380 (1381, 5477): If user-defined characters are ignored, this almost corresponds to CPGID 1382 over GR (as it is in CCSID 1383), except the IBM extensions have lead byte 0x8C not 0xFE (but the same trail bytes). Lead bytes 0x8D through 0xA0 are used for user-defined characters (with the usual trail bytes), as opposed to being infilled in the unused space in the main plane as they are in CPGID 1382, meaning a full-sized set of 1880 user-defined characters can be defined; this relatively meagre benefit at the cost of colliding with GBK (which itself also provides an expanded set of user-defined characters) was presumably not always seen as worth it, considering that ICU provides as CCSID 1383 codec but not a CCSID 1381 one, nor any CPGID-1380-based one. CCSID 1381 includes some single-byte extensions that CCSID 5477 does not.
- 947 (950, 1370, 5046): Like MS-950, this is based on Big5-ETEN; however, the extensions are mutually exclusive since IBM and Microsoft include non-overlapping subsets of the ETEN extensions. IBM also includes their own extensions in CPGID 947 with trail bytes 0x81–A0, outside of the usual Big5 trail byte range. User-defined ranges have considerable overlap though. The rest of the ETEN extensions (including the part included by Microsoft) are only available in CPGID 1374, not 947. CCSID 1370 adds both single-byte and double-byte Euro signs. CCSID 5046 excludes three standard Big5 characters, while including IBM extensions that arguably duplicate them, since the IBM extensions correspond to older reference glyphs of those characters.
- 951 (949, 5045): Entirely unrelated to Microsoft's internal use of the code page number 951 within their HKSCS-2001 patch for MS-950. Like Windows-949, CCSID 949 is an extension of EUC-KR; however, the similarities end there. CPGID 951 is a superset of CPGID-971-over-GR; as defined by C-H 3-3220-125 1992-09, it merely added additional user-defined characters with the lead bytes 0x8F through 0xA0 and the usual trail bytes, thus supporting a full-sized set of 1880 user-defined characters as opposed to the 188 available in CPGID 971. CCSID 5045 furthermore excludes the extra user-defined characters, including only the 188, although both CCSID 949 and 5045 include single-byte extensions. However, at some point between that document (dated 1992) and the IBM-949 ICU mapping (dated 1999), this seems to have been revisited, and lead bytes 0x9A–A0 are now used in CPGID 951 for characters from CCSID 933's repertoire which are unavailable in CPGID 971, reducing the number of available user-defined characters to 1227.
- 941 (943, 9135, 13231): Unlike CPGID 301, this makes the codepoint swaps made in the 1983 edition of JIS X 0208, and includes the two additions from the 1983 edition that duplicated existing IBM extensions. Accordingly CCSID 13231, IBM's CCSID for 1997 standard Shift JIS, uses CPGID 941, not 301. CCSID 9135 matches the repertoire of CCSID 932, but uses CPGID 941 rather than 301. CCSID 943 is the full Windows-31J / MS-932.
- 1385 (1386, 1392, 5482): CCSID 1392 (GB 18030) also includes the quadruple-byte CPGID 1391, which the rest do not. CCSID 5482 omits user-defined characters.
- 1372 (1373) or 1374 (1375, 5471; further CCSIDs 9567 and 13663 not listed in table due to space): The formerly IBM-published CCSID descriptor for CCSID 1375, which uses CPGID 1374, bears the note "this CCSID is intended to match MS-950". It clearly is not, since it supports HKSCS-2008; it is theoretically a growing CCSID, although since HKSCS-2016 (and MSCS expanding upon it) abandoned the assignment of Big5 code points for HKSCS characters, it is probably now de facto frozen at its current MCCSID (CCSID 13663 for HKSCS-2008). The CCSID which does correspond to MS-950 is CCSID 1373, whose CCSID descriptor was not published, but which clearly exists considering there's an IBM-supplied ICU mapping for it; it would seem to use CPGID 1372, considering the latter is named "MS T-Chinese Big-5 (Special for DB2)".
- 1362 (1363, 5459, 9555): CCSID 1363 is the full Unified Hangul Code / Windows-949, plus the 188 user-defined characters from CPGID 971. CCSIDs 5459 and 9555 are constrained to the repertoire of CCSIDs 933 and 944, barring user-defined characters; they differ in that CCSID 5459 includes the 188 user-defined characters, while CCSID 9555 includes no user-defined characters.
- 952 and 953 (954, 5050, 33722; further CCSID 37818 not listed in table due to space): CCSID 5050 is constrained to the repertoire of CCSID 932 and CCSID 33722 is constrained to the repertoire of CCSID 942, i.e. both omit most of JIS X 0212, while CCSID 954 includes all of it. CCSID 37818 extends CCSID 954 by adding NEC row 13 (this corresponds to an enlargement of CPGID 952 made in the 2009-12 edition of C-H 3-3220-127; it is absent in the previous 1993-03 edition). In all cases, CPGID 952 does not include the NEC Selected IBM Extensions, and instead CPGID 953 includes an extension range including the IBM extensions otherwise unavailable in JIS X 0212; however, this uses a different (and colliding) layout for them than the OSF's eucJP-open's "IBM Extensions" scheme does.
- 1382 (1383 and 5479): CCSID 5479 is pure GB/T 2312-80 EUC-CN (i.e. the
GB2312label in the strict sense). CCSID 1383 includes IBM extensions with lead byte 0xFE, and fills all otherwise-unused positions with 1360 user-defined characters. - 960 and 961 (964, 5060): Since this is EUC-TW based mainly on CNS-11643-1986 and defined as a transformation of the other Traditional Chinese encodings, not CNS-11643-1992 (leave alone CNS-11643-2007), CCSID 964 consists for the most part of standard inclusions in planes 1 and 2, 6204 user defined characters in plane 12, and IBM extensions in plane 13 (the latter two, of course, collide with the use of those planes in CNS-11643-2007). CCSID 5060 excludes the user defined characters and IBM extensions. In either case, plane 1 is always accessed from CPGID 960, not CPGID 961, i.e. plane 1 is accessed through two-byte EUC sequences, not four-byte EUC sequences.
- 971 (970 and 5066): CCSID 5066 is pure EUC-KR, while CCSID 970 includes 188 user-defined characters within the main plane, with lead bytes 0xC9 and 0xFE. There was no space to include the IBM extensions within the EUC plane, hence they are only available in CPGID 951, not CPGID 971.
File history
Click on a date/time to view the file as it appeared at that time.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date/Time | Thumbnail | Dimensions | User | Comment | |
|---|---|---|---|---|---|
| current | 15:03, 13 July 2024 | | 1,086 × 713 (10 KB) | HarJIT | Simplify SVG code since it was evidently no longer rendering correctly |
| 01:14, 4 November 2022 |  | 1,018 × 669 (142 KB) | HarJIT | Shift GB is confirmed. | |
| 07:42, 3 January 2022 |  | 1,018 × 711 (143 KB) | HarJIT | Mention 1391 and be marginally less confusing elsewhere. | |
| 16:12, 31 December 2021 |  | 1,018 × 711 (142 KB) | HarJIT | CPGID 1372 for CCSID 1373. | |
| 23:42, 28 December 2021 |  | 1,018 × 711 (142 KB) | HarJIT | Restore background. | |
| 23:41, 28 December 2021 |  | 1,018 × 711 (142 KB) | HarJIT | C-H 3-3220-126 2016-04 explicitly names C-H 3-3220-126 1999-04 as the previous edition, so there were no intervening editions. | |
| 13:16, 29 November 2021 |  | 1,018 × 711 (142 KB) | HarJIT | 951 also collides. | |
| 11:34, 29 November 2021 |  | 1,018 × 711 (142 KB) | HarJIT | Apparently the triple dagger freaks out Commons' SVG renderer. | |
| 11:30, 29 November 2021 |  | 1,018 × 711 (144 KB) | HarJIT | Footnotes. | |
| 14:57, 28 November 2021 |  | 1,018 × 567 (134 KB) | HarJIT | Include the reserved region after the last allocation but before the EUDC region in IBM-927's main plane range. |
File usage
The following 4 pages use this file:
{kind=link}